自然言語処理とオープンデータ
はじめに
インターネットや多種多様なセンサーからは、日々大量のデータが産出され、様々な分野で活用されています。
例えばTwitterなどのリアルタイム性の高いソーシャルメディアは企業の商品開発や販売戦略等のマーケティング分野で活用が進んでいますが、MKIでもTwitter等から収集されたビッグデータを扱う英国Black Swan Data Ltdの分析ツールの、日本語化や販売を行っています。
こうしたTwitter等のテキストデータを分析する際、最も基礎となる技術が、今回ご紹介する「自然言語処理」です。
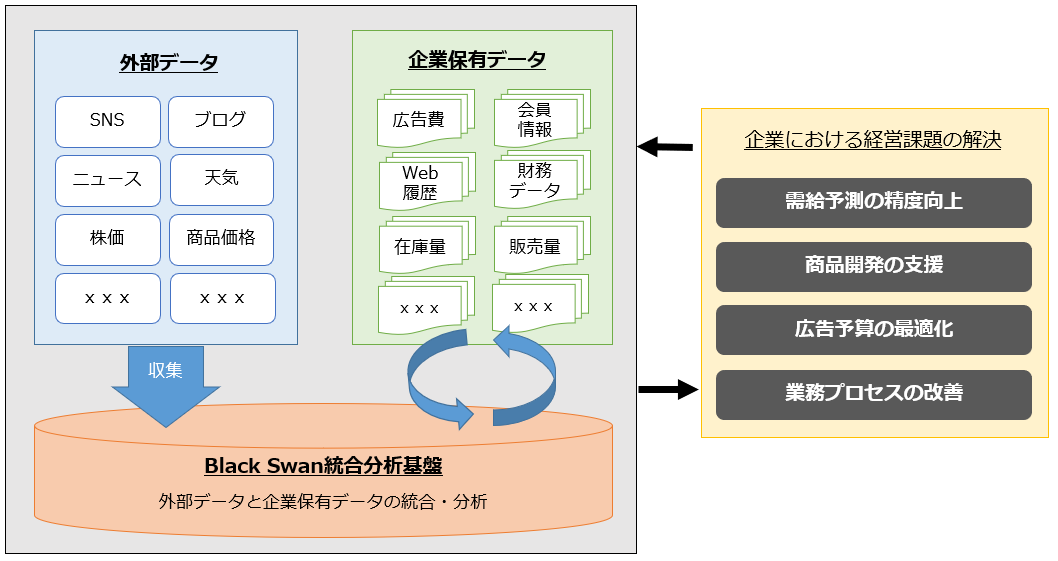
■Black Swan Data Ltd ビッグデータ分析サービスの概要
自然言語処理とは
ICTの分野に携わっている方なら「自然言語処理」という言葉をよく耳にすると思いますが、では「自然言語処理」とは?と尋ねた場合、人によって認識が異なることが多いです。
「自然言語処理」を一言で説明するならば、「書き言葉や話し言葉などテキストデータ化された自然文をコンピュータで処理する為の技術」という点は問題ないと思いますが、「自然言語処理=形態素解析」と考える人もいれば、広義の意味で「機械翻訳」まで含めて考える人もいます。
自然言語処理の分野は日々進化しており、従来から存在する形態素解析、構文解析、意味解析をベースに、それらの要素技術を掛け合わせて文書分類、自動要約、機械翻訳、音声認識、情報抽出、ネガポジ分析等の新しい技術が生み出されています。
個人的には、広義の意味で「自然言語処理とは、テキストデータから従来の要素技術や新しいICT技術を組み合わせて、テキストデータの知識を整理する・新しい知識を抽出する為の要素技術」と考えています。
自然言語処理の課題
自然言語処理は難しいと言われることが多いですが、その理由の一つは、前処理の複雑さにあると思われます。
自然言語処理がうまくいくためには、前処理として自然文をきれいに単語分割することが必須であり、ここがうまくいかずに入力データにノイズが含まれている場合、後続の処理でどんなに素晴らしいアルゴリズムを用意しても、思ったような結果は得られません。
前処理は辞書に依存しますが、辞書構築は人手を介することが多く、非常に手間がかかります。例えば業界の専門用語を単語分割するには、予めその専門用語を含んだ辞書を用意しておく必要があります。AIや機械学習的な手法を用いて辞書構築を自動化しようとする取り組みもあるようですが、革新的な成果が上げられていないのが現状のようです。
オープンデータ化の流れ
一方で、古くからティム・バーナーズ=リーによって提唱されたセマンティックウェブ、つまりデータウェブ(Linked Open Data)は、設計されたオントロジー※1に従ってテキスト情報をグラフ構造で整理したものであり、高度な自然言語処理や辞書構築を行わずに、テキスト情報の知識を抽出できると考えられています。Linked Open Dataの特徴の一つに推論を行うことが可能であることが挙げられます。推論を予測という言葉に置き換えることが可能ならば、例えば、AIの判断のプロセスを理由付け出来ることは安全性の為に必要と考えられていますが、Linked Open Dataは、グラフ構造により判断プロセスが可視化されるので、AIとは異なったアプローチによる予測・推論が可能なツールという意味で、有用な技術の一つと思われます。
※1 オントロジーとは
「哲学用語で存在論のこと。ものの存在自身に関する探究、あるいはシステムや理論の背後にある存在に関する仮定という意味である。これから派生して情報科学等でも用いられる。」「人工知能分野をはじめとするコンピュータの世界では、『概念化の明示的な仕様』と定義されることがある。」(「オントロジー」『フリー百科事典 ウィキペディア日本語版』(https://ja.wikipedia.org/)2019年7月1日 (月) 14:41 UTC)
Linked Open Dataの現状
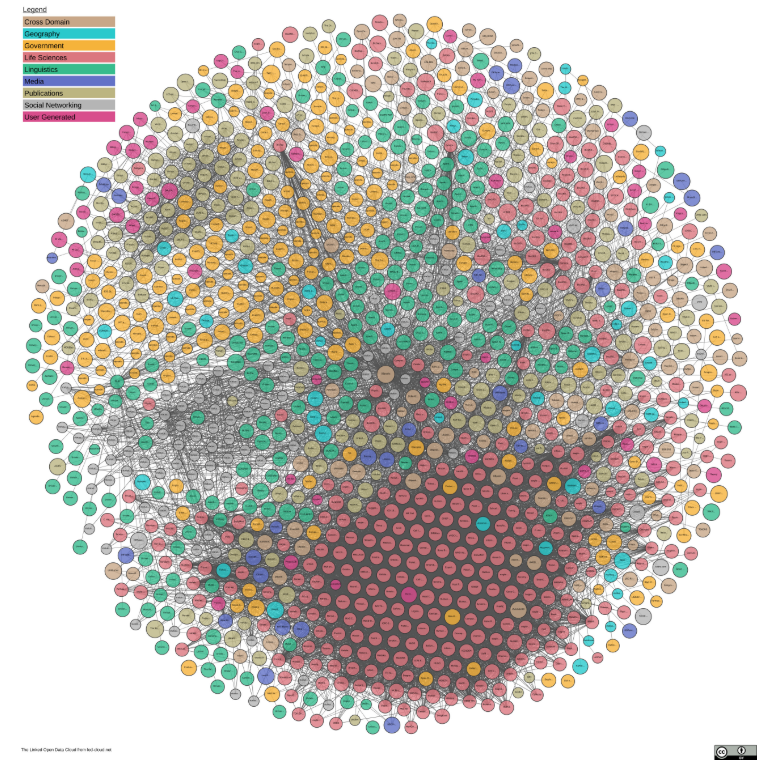
以下の図は、世界のセマンティックウェブ化されたデータベースの概観図で、データベース同士の繋がりを表した図です。
(出典:https://lod-cloud.net/)
 |
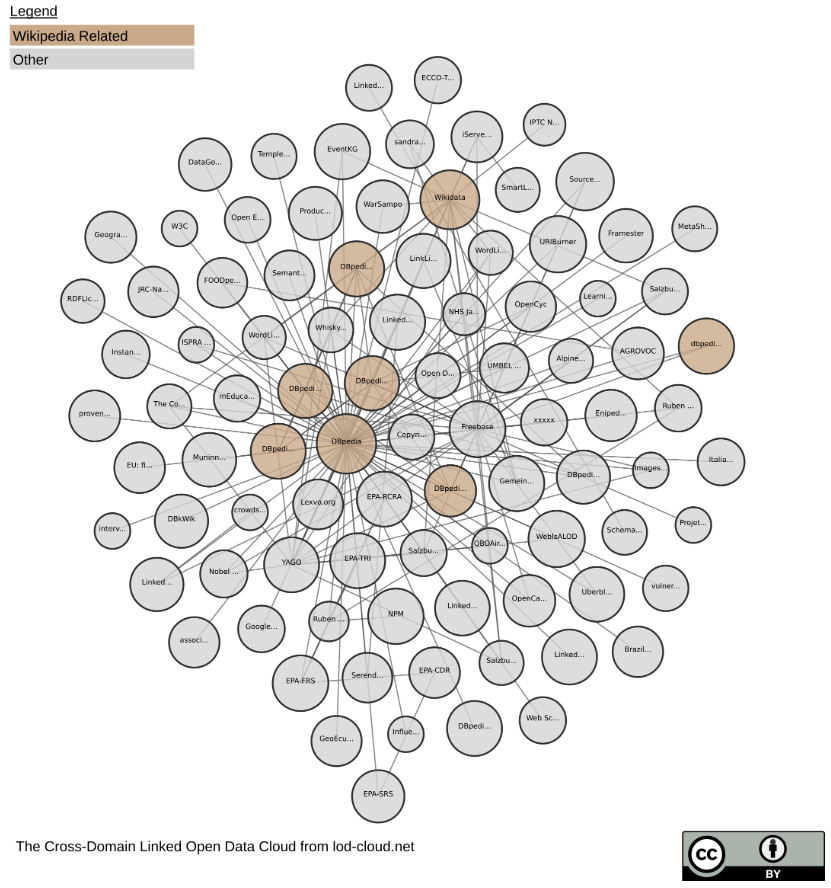 |
| ■ The Linked Open Data Cloud from lod-cloud.net | ■The Cross-Domain Linked Open Data Cloud from lod-cloud.net |
昨今のオープンデータの流れと共に、海外の公共機関を中心に、多くのデータがLinked Open Data化されつつありますが、まだまだ発展途上の状況ですので今後の拡がりに期待したいです。
一方国内の興味深いトピックとして、2018年に、一般社団法人 人工知能学会のセマンティックウェブとオントロジー研究会(SWO研究会)主催で、シャーロック・ホームズの推理小説を題材にLinked Open Dataの技術を用いて犯人捜しをする、「第1回ナレッジグラフ推論チャレンジ2018」というコンテストが開催されました。
(尚、現在「第2回ナレッジグラフ推論チャレンジ2019」の応募受付中です。コンテストについて詳しくはこちらのサイトをご覧ください。https://challenge.knowledge-graph.jp/)
まとめ
自然言語処理の発達は、まだ多くの可能性を秘めています。例えば情報リソースの多くはインターネットを介して得られますが、従来の文字情報による辞書構築に加え、センサー等から産出される画像情報や音声情報を用いて辞書構築を行い、それらを掛け合わせることで、あたかも人間が新しい言葉を認知するがごとく、コンピュータが新しい言語を認知するような自然言語処理の技術が開発される日が来るのではないかと期待しています。
執筆者

杉崎 太一朗
先進・共創事業グループ ソリューションナレッジセンター
エンゲージメント推進部 エンゲージメント推進室
現在、データ分析を活用した新ビジネスモデルを構築すべく活動中
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。