IPFS ~ハイパーメディアプロトコル~
2021/01/14
次世代基盤第一技術部 第二技術室
はじめに
■ 珍しい生き物
みなさんはカモノハシをご存知でしょうか。
哺乳類は恒温動物で体温は変化しません。ところがこの動物は25~36度まで体温が変化、卵で産んで乳で育てるという珍しい哺乳類です。

■ 珍しい…
今では誰もが利用するインターネットも、かつては同様の存在でした。
国際的な通信網はモールス信号による低速度な符号ベースの電信網が主流でした。
その後1950年代にはテレックス網を使い、遠隔地のコンピュータ間の通信や端末との通信を行うようになりました。
そして1982年にはTCP/IPが標準化され、TCP/IPを採用したネットワーク群を世界規模で相互接続するインターネットという概念が生まれました。
■ テキストを超えるもの
またこの頃、複数の文書を相互に関連付け/結び付けることから通常のテキストを超えるという意味でハイパーテキストが生まれました。
この紐づけをハイパーリンクと言い、記述する言語としてHTMLが体系化されました。
■ HTTPの登場
ハイパーテキストによって情報提供する者はサーバを公開し、一般利用者はHTMLを解釈して表示するブラウザを介して情報を閲覧する仕組みができました。
世界中を蜘蛛の巣(web)に見立てて「World Wide Web」、提供サーバを「Webサーバ」と呼びます。 
そして、ハイパーテキストをやりとりするプロトコルを、HTTP(HyperText Transfer Protocol)と言います。
■ Webは場所を示す
現在インターネットで情報にアクセスする場合、https://www.xxx.com/aaa/index.htmlといったURLを指定してアクセスします。
このURLの意味するところは「www.xxx.comというWebサーバにあるaaaというディレクトリの中のindex.htmlというファイル」で、つまりは取得したい情報がある「場所」(サーバの名前、ディレクトリの名前、ファイル名)を指定しているものです。
このように欲しい情報が存在する「場所」を指定して情報にアクセスする方法は「ロケーション指向」と呼ばれ、HTTPはロケーション指向のプロトコルです。
■ Webの弊害
この技術には、大きな欠点があります。Webをデッドリンク(リンク切れ)にする性質があります。
1つの場所から1つのファイルをダウンロードするため、ミラー(複製)サイトなどがない限り、そのサイトが停止するとデータを取り出せなくなります。これは大変不便です。
そこで、この情報に全ての人が恒常的にアクセスすることを可能にするため、Webサーバやコンテンツの管理に多大なコストが投じられます。またコンテンツは、閲覧する側の政府の検閲対象になり得ることから、必要な情報が得られなくなる可能性があります。
不便だと思いませんか?
欲しいコンテンツの名前が判れば、どこからでも取り出せる。
デッドリンクなんて起こりません。
そんな都合の良い仕組みがあったら良いと思いませんか?
あるんです。
それがIPFSです。
IPFSとは何か
■ IPFS(InterPlanetary File System)
日本語では「惑星間ファイルシステム」と訳され、米Protocol Labsにより開発が進めれられているP2P※1ネットワーク上で動作するハイパーメディアプロトコルとその実装です。
現在のインターネットで主要なプロトコルであるHTTP(Hyper Text Transfer Protocol)を補完または置換するプロトコルとして位置付けられ、コンテンツ指向型のプロトコルであるところに大きな特徴があります。
※1 P2P(Peer to Peer)はコンピュータ等の複数の端末がサーバを介さずにファイルを共有することができる通信技術やソフトウェアを指します。
■IPFSはコンテンツ指向型プロトコル
実は、IPFS は BitTorrent※2 に似た特性を持っています。
1 つの場所から 1 つのファイルをダウンロードするのではなく、いわゆる Torrent スウォーム※3を採用しているので、多数のシャード(断片)に分割されたファイルを複数の場所から同時にダウンロードできます。IPFS の場合、Torrent スウォームに相当するものは分散ハッシュテーブル(DHT、Distributed Hash Table)で構成されています。また、ブロックチェーン技術を使うと、データ自体ではなく保持されているデータのハッシュを記録できます。ハッシュは不変のタイムスタンプで、検索も可能です。
同一の内容であればどのサーバ上から取得したか?どの名前のファイルから取得したかなどという入手先はほとんどの場合で重要ではありません。
そのためその情報の「場所」ではなく、「こういう内容の情報」というコンテンツの内容自体を直接指定して情報にアクセスする仕組みを考えることができます。
これが「コンテンツ指向」になります。
※2 BitTorrentとはP2Pを用いたファイル転送用プロトコルおよびその通信を行うソフトウェアを指します。
※3 スウォームは、同じファイルを扱うコンピュータのグループ全体を指します。
■ 場所は知らなくても良い
従来のWebに見られる様々な弊害やリスクを根本的に解決するために、IPFSでは「コンテンツ指向型」のプロトコルを採用しています。
例えば書籍、宮沢賢治の「銀河鉄道の夜」を読みたいと思ったとき、その書籍が読めればそれをどこから入手したかを気にすることはありません。近所の本屋さんで買っても、Amazonで買っても、図書館から借りても同じ内容を読むことができます。
インターネット上の情報も同じです。
■IPFSのメリット
コンテンツ指向プロトコルの仕組みは古くから研究されており様々な実装方法が提案されています。
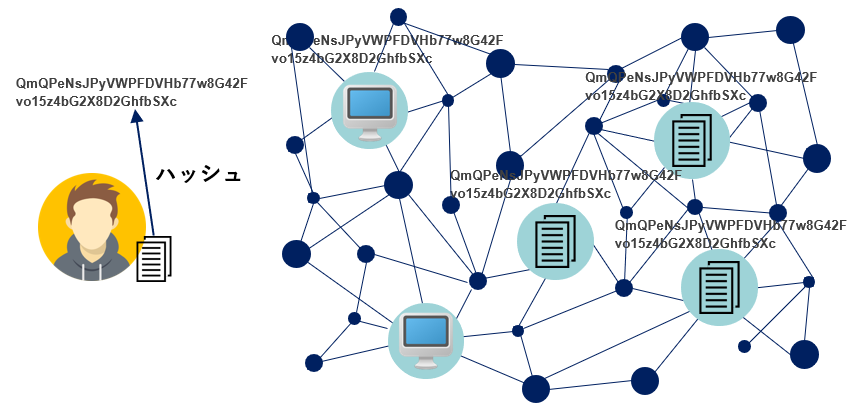
その中でもIPFSではSHA(Secure Hash Algorithm)などの暗号ハッシュ関数を利用してコンテンツのハッシュ値を求め、それをそのコンテンツのIDとして利用する方法を採用しています。(2048 bit)
ハッシュ関数により得られるハッシュ値は、同じデータであれば必ず同じハッシュ値が得られる一方、少しでも異なるデータからはまったく異なるハッシュ値が得られる特徴があります。
そのためこのハッシュ値をキーにアクセスするIPFSには、ロケーション指向であるHTTPプロトコルでは得られない様々なメリットが発生します。
【IPFSのメリット】
| 耐障害性 | IPFSでは、コンテンツのハッシュ値を指定しそのコンテンツがある場所(サーバ等)は指定しません。そのため、たとえオリジナルのサーバが何らかの原因でダウンしていても、同じハッシュ値(=コンテンツ)のデータを持っているどこか他の場所から同じ情報を取得することができます。 |
| 負荷分散 | コンテンツの場所を指定しないIPFSでは、同じコンテンツを複数のサーバから取得できる場合、より近いサーバから取得します。そのため一つのサーバに負荷が集中することを防ぐことが可能になります。 |
| 耐検閲性 | ロケーション指向ネットワークでは、その情報のある場所(サーバ)へのアクセスを遮断するだけで検閲が可能でした。一方、コンテンツ指向ネットワークでは同じコンテンツは無数のサーバで保持されることが可能であり、どこかのサーバがアクセスを遮断されても、代理の他のどこか別のサーバから同一の情報が取得可能になり、検閲を難しくします。 |
| 耐改ざん性 | データのハッシュ値をキーにデータにアクセスするということは、データの改ざんを不可能にします。データを取得した人はアクセスしたデータのIDであるハッシュ値と、そのコンテンツから得られるハッシュ値を比較することで容易にコンテンツの正当性を検証することができるからです。 |
■IPFSの仕組み
鍵があれば複合可能というのが普通の暗号化です。ハッシュの場合はハッシュだけもらっても復号は不可能、少なくとも極めて困難です。どれだけ困難かと言うと、何文字かわからないですが、ありとあらゆる可能な限りの英文を1個ずつ計算して、いつかそのハッシュが出てくるまでやれば戻せます。
総当たりで存在している文章を全部ハッシュします。天文学的な数値の確率で、もしかしたらこれが当てられてしまうかもしれない。そういう意味だと100%復号不可能とは数学的には言えない。しかし、極めて困難というものがハッシュという技術になります。
IPFSの仕組みですが、これはファイルシステムなので、ファイルを格納するための仕組みになります。
P2PデータストレージシステムとしてIPFSを使用すると、各ユーザ(ピア)はローカルで必要なデータをホストできます。IPFSに新しいコンテンツを最初に追加するときは、実際にはIPFSプロトコルを介した共有に適した形式で自分のマシンに設定するだけです。通常、自分のコンピュータにIPFSをインストールし、そこにIPFSの新しいインスタンス(ノードとも呼ばれます)を作成します。これはコンテンツアドレス(CID、Content ID)によって参照される、データがローカルに存在する場所です。これをローカルリポジトリと呼びます。IPFSに保存されるデータにはさまざまな形式がありますが、最も一般的な使用例の1つは、従来のファイルの共有です。
ネットワーク接続が確立されているときにデータまたはファイルをピアと共有することを選択できますが、特定のリソースをホストしているのが自分だけの場合、マシンがオフラインになるとピアはそのリソースを使用できなくなります。同じファイルをホストする複数のピアを持つことで、それらをより簡単に利用できるようになり、CID(Cryptographicハッシュによって作成された一意のコンテンツ識別子)を使用することが、このシステムを安全なものにします。
ローカルリポジトリをLAN内で分散する場合は、全てのピアは同じネットワーク内に居ます。またこれらをローカルのスウォームと表現できます。実際に外部へ公開するWebサーバなどのコンテンツは、不特定多数の外部のピアが対象になります。公開範囲は、このピアをどこまで広げるかで制御できます。通常はIPFSゲートウェイを構築し、GETのみなのかPOSTも可能にするのかなどの細かい設定をした専用のサーバを用意します。
ピアの設定を行わない場合は「公開扱い」となりますので、注意が必要です。
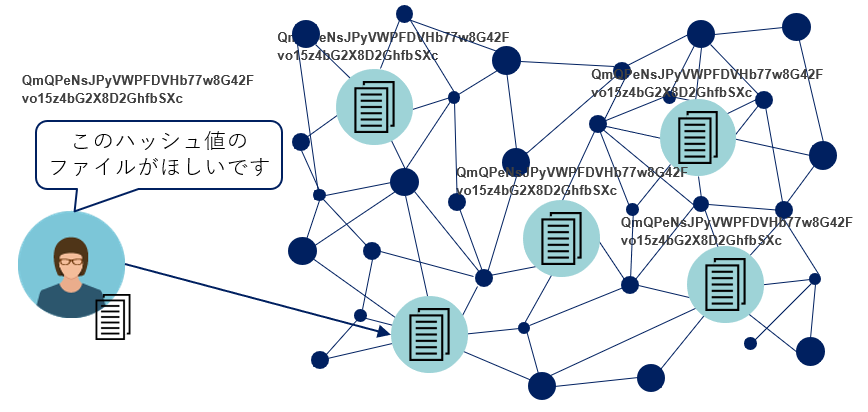
一度公開したデータは複数ピアに分散されているため、完全な削除は困難になります。そのデータのハッシュ値が不用意に漏れると、だれでも中身を自由に閲覧可能になってしまいます。
これが参照の仕組みです。
Webの短所として、人気のあるコンテンツにはアクセスが集中しやすいという点が挙げられます。
負荷が上がることでサーバダウンを引き起こしたり、あるいは維持コストの増加により、コンテンツそのものが削除されることもあり、人気のコンテンツほど失われやすいとも言えます。
IPFSではこうした問題を回避するために、キャッシュという仕組みを用意しています。人気のあるコンテンツほど多数のサーバによってスウォームが作られやすくなり、結果として、単一サーバへの負荷が軽減され、且つ、複数サーバからダウンロードが可能になるためアクセスのパフォーマンスも維持されるというわけです。
IPFSの性質上、スウォーム全体から確実にコンテンツを削除することはできません。そのため先ほどの仕組みを発展させ、人気のないコンテンツはキャッシュされるサーバが少なくなり、いずれは自然消滅するという作りになりました。JAVA言語でいうところのガベージコレクション(Garbage Collection; GC)と似た仕組みを持たせています。各ノード毎にキャッシュする時間を指定できるようになっています。
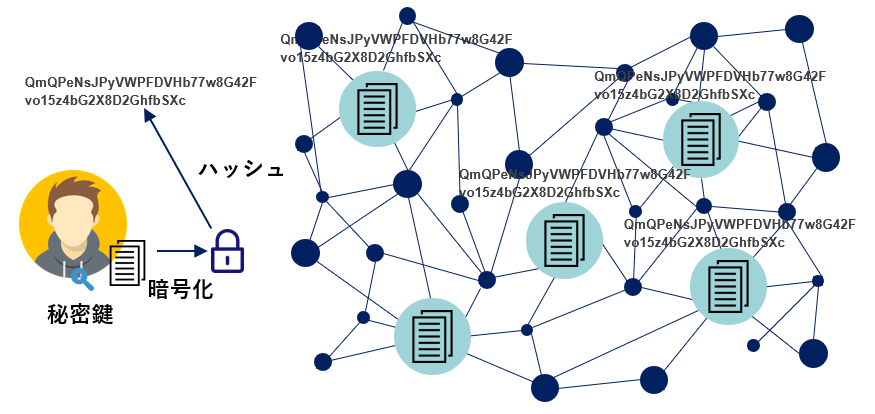
通常はまず秘密鍵でファイル自体を暗号化します。暗号化したもののハッシュを取って、それをIPFS上に置けば、各ノードは自分が何のデータを受け取っているのかがあまりわからないので、それを取っておいてもしょうがないということになります。秘密鍵が外に出回らなければ、実質元のデータに戻すことは不可能となります。
■普及が始まったIPFS
このように従来のHTTPプロトコルにはないメリットを有したIPFSは、まだ実験段階にも関わらず実際のサービスでの利用が始まっています。
例えば個人用ホームページのホスティングの草分けであるNeoCitiesは2015年にそのホスティングにIPFSを利用することを発表しました。
またP2Pの分散型ファイルシステムという特徴から、IPFSはEthereumなどのブロックチェーン技術との相性がよく、それらを組み合わせて構築される様々なサービスが開発され始めています。
後発でも、やりようによっては、それなりのサービス展開が可能と考えられます。
技術面から見たIPFS
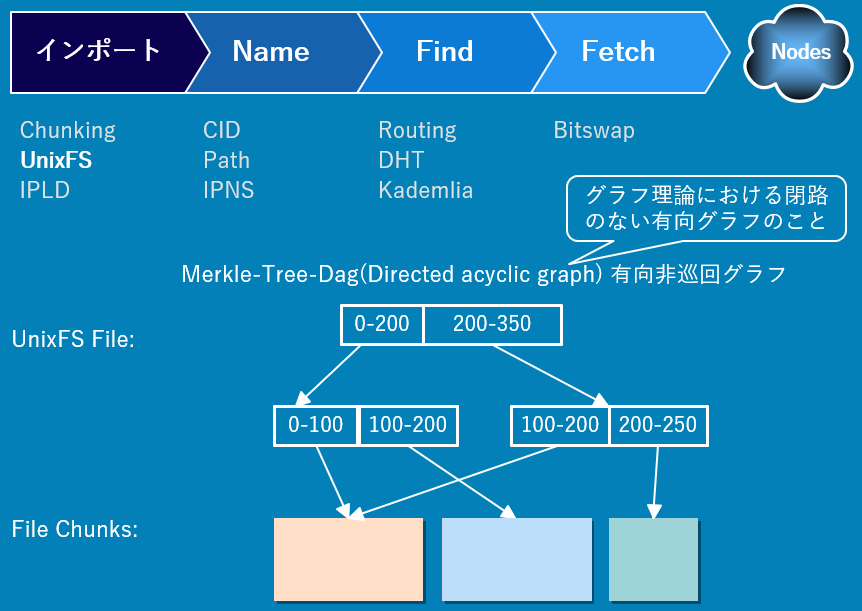
IPFSではデータをアップロードする際に、256KBより大きければchunking(データを分割)し、UnixFS(Unix File System)形式でファイルとそのすべてのリンクとメタデータを表すためのブロック(もしくはブロックのツリー)を形成します。その後、IPLD(InterPlanetary Linked Data)と呼ばれる仕組みによって、アドレス指定およびリンク可能な分散型データ構造(Merkle DAG、 Directed Acyclic Graph:有向非巡回グラフ)を作成します。
ブロックチェーンは、各ブロックが鎖(チェーン)のように繋がることでデータを連続的に保管する台帳技術です。さらに各ブロックには、多くのトランザクション(取引)データが格納されています。ブロックチェーンでは、その多くの取引データを「マークルツリー」という技術を利用することでブロックヘッダに要約して書き込んでいます。マークルツリーはファイルのような大きなデータを要約した結果を格納するツリー構造の一種で、主に大きなデータの要約と検証を行う際に使用されます。その計算にはハッシュ関数が利用されていることから、ハッシュ木とも呼ばれています。
マークルツリーの基本形は2つのデータを1つにまとめる形になります。例えば、AとBという2つのデータがあるとします。まずは、Aのハッシュ、Bのハッシュをそれぞれ計算します。このAのハッシュ、Bのハッシュそれぞれを足し合わせた値のハッシュをとったものが頂点の値になります。
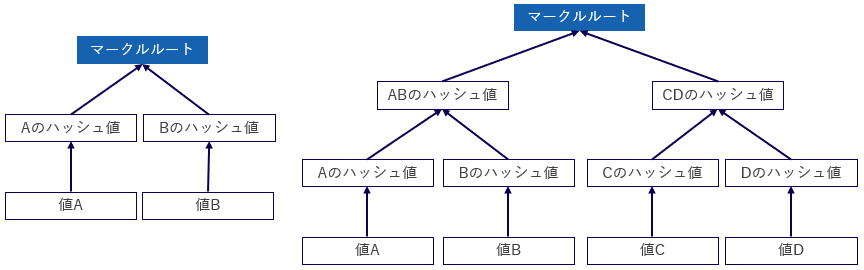
マークルツリーが実際に使われる場合は、たいてい複数段のツリー構造で構成されており、2段、3段と2個ずつハッシュをまとめていきます。そして最終的に得られた頂点のハッシュ値はマークルルート(マスターハッシュ)と呼ばれています。
マークルツリーには、どんなデータを入力しても一定の長さの値を返すハッシュ関数を使用していることから、どんなに大きなデータ、どんなに多くのデータを入力しても最終的に得られる値は一定のデータ長になるという特徴があります。
言い換えると、2個のデータを要約しても、65536個のデータを要約しても、最終的には同じデータ長にまとめることができます。また、計算方式が単純であるため、比較的簡単にマークルルートの値を得ることができます。この特性を使い、予め保存されたマークルルートの値と要約元のデータがあれば、新たに要約元のデータから算出したマークルルートの値と、予め保存されたマークルルートの値を比較することで、要約元のデータの検証にも使うことができます。この仕組は改ざん検知の際に強力な力を発揮します。
IPFSではこれらが Node-Node間(P2P)で存在する状態を、マークルフォレスト(森)と呼び、これを検索する仕組みが先にお話しした IPLDです。
IPFSの特徴としては、CID、パス、ルーティング、データ配布の4つが挙げられます。
① CID
IPFSでは各データにCID(Content Identifier)と呼ばれるラベルが付与されます。
このCIDはコンテンツのハッシュに基づいています。コンテンツ毎に個別のCIDが付与されており、同じコンテンツを異なるIPFSノードに追加した場合も、それぞれのコンテンツのCIDは同じになります。
② パス
IPFSでは、URLではなくパスでコンテンツにアクセスします。
たとえば、/ipfs/QMfoo/index.htmlのような表記のパスです。また、IPFSではファイルを編集するとハッシュが変わるため、IPNS(InterPlanetary Name Systems)を利用することでファイルのハッシュの代わりに自分のPeerIdを結びつけて利用します。
③ ルーティング
ルーティングテーブルを各ピアが保持することでルーティングを決めますが、P2Pネットワークでは各ピアが接続しているため、ルーティングテーブルが巨大になるという懸念があります。そこで、IPFSではルーティングテーブルを細かく分けて分散化(DHT(Distributed Hash Table):分散ハッシュテーブル)しています。
そして、アルゴリズムに合わせて分散化されたルーティングテーブルの一部を知ることができます。距離のメトリックとして、XOR(Hash(CID)、Hash(Peer))を用いており、自身が知っている一番近いピアに問い合わせをして、アクセスしたいデータがどこにあるかを発見できます。
④ データ配布
IPFSではBitTorrentに強く影響されたBitSwapプロトコルがあり、これに準拠したピア間のブロック交換によってデータが配布されます。各ピアは自身が所持したいブロックリストと、自身が提供できるブロックリストを保持することで、ピア間でデータを交換することができます。
おわりに
■IPFSは様々な情報をバックアップできる
紀元前4世紀から始まった貨幣制度は、地域ごとに競い合い、その後中央銀行で発行され、人々はその価値を信じてきました。こう考えると暗号資産は、分散型台帳であると言えます。
例えば図書館。アレクサンドリア図書館は全書物を収集してきた典型的な中央型ストレージで、Amazon、IBM、Microsoftなどは現代のアレクサンドリア図書館であるといえます。
このように、中央集権は偉大なものを創造し、分散型は永遠のものを創造すると言えます。
そこで、IPFSとFilecoin※4は人々の情報をバックアップする強力な土台になる分散型ストレージになると考えられます。
※4 Filecoinとは、Protocol Labsが中心となりオープンソースで開発が進められている分散型のファイルシステム。
■おわりに
今回は、HTTPに代わる新プロトコルとして、また新たなファイルシステムとしてのIPFSについて紹介いたしました。個人情報や機微情報の扱い、データの外部流出防止、相互接続性、負荷分散など幅広い技術です。身近なサービスへの適用に多くの可能性を秘めており、三井情報でもサービス化に向けて環境構築ならびに検証を進めているところです。
是非今後の動向に注目してください!
執筆者

入谷 徹
次世代基盤第一技術部 第二技術室
非接触バイタルソリューション、感情分析/ストレス分析、音声チャット、リアルタイムキャプチャの実現化に従事。
|
|
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。