サーバを監視しダウンタイムを回避する新機能群
ーコラムー
2020年8月27日号
Cloudflareを導入する際に、サイトの異常検知についてご質問を受けたことがあるのですが、これまでは異常検知や発報する機能はなく、別途仕組みを用意するような提案しか出来ませんでした。しかし、最近Cloudflare単体でオリジンサーバの異常を検知できる機能やダウンタイムを回避する機能が加わりましたのでご紹介いたします。
スタンドアロンヘルスチェック
オリジンサーバに対して死活監視を行い、障害検知時や復旧時にEメールで通知を行う機能です。 以前に別の記事で解説したロードバランサー機能にも同様の機能が具備されており(これをMonitorと言います)、Monitor機能の場合は障害の発生や復旧の検知を負荷分散の動作へ反映させる目的で使われます。 スタンドアロンヘルスチェックの場合は、ロードバランサー機能を購入していなくとも使うことが出来る機能で、Eメールでの通知のみ行うことが出来ます。 ヘルスチェック機能の詳細は、Monitorと同様の機能が具備されており、レイヤー7での死活監視を行うことが出来ます。
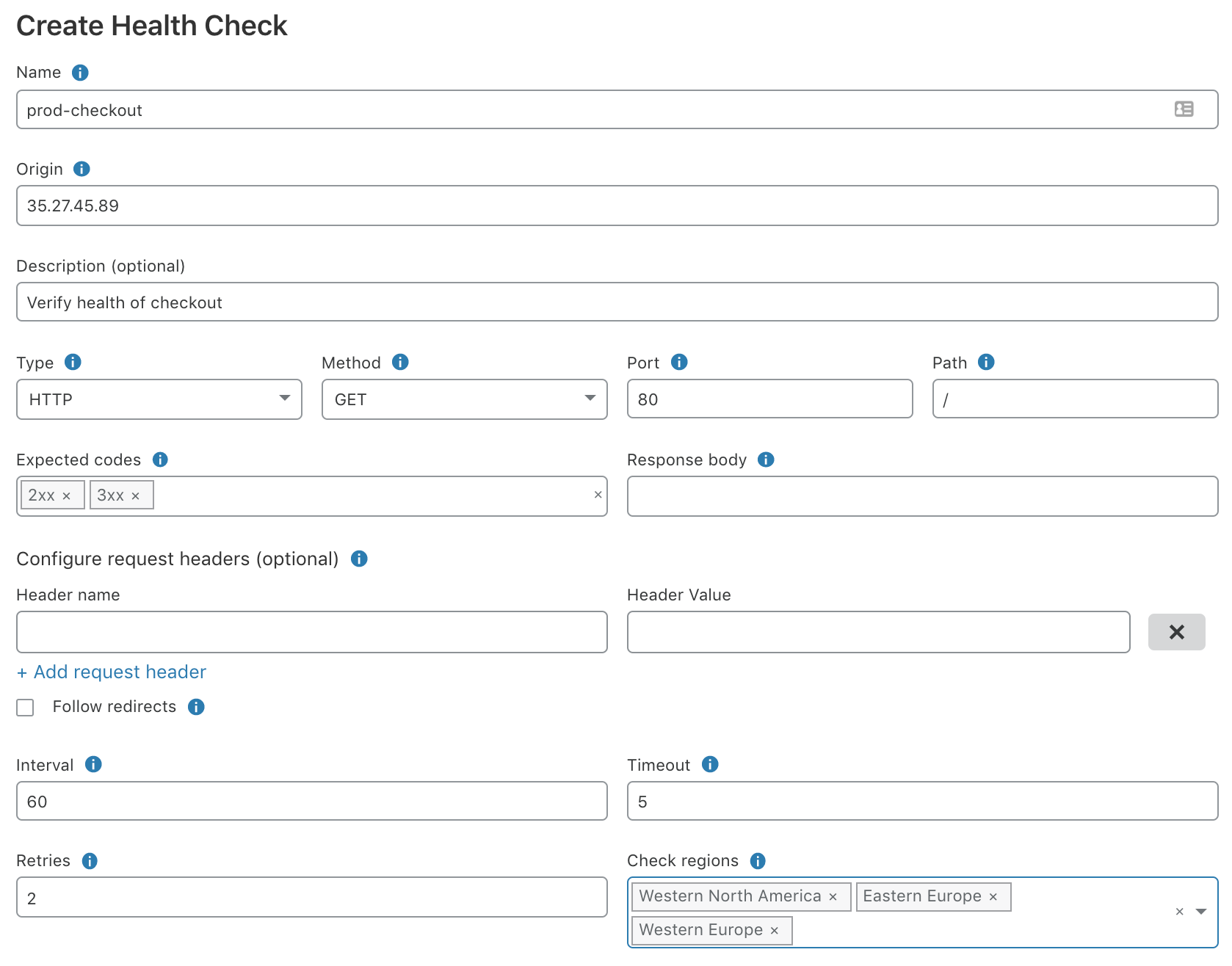
主な設定項目としては、死活監視を行う対象のオリジンサーバのホスト名又はIPアドレス、Type(TCP/HTTP/HTTPS)、HTTPメソッド、TCPポート番号、Path、期待するレスポンスコード、期待するレスポンスボディに含まれる文字列、死活監視の実行間隔、タイムアウト、リトライ回数などです。 レスポンスボディに含まれるべき文字列までチェックできるため、Pathとしてcgiを指定すればアプリケーションサーバやデータベースまで含めた監視を行うことが出来ます。
検知時には以下のような本文を持ったシンプルなEメールが届きます。
2020-03-30 06:08:16 +0000 UTC | Down | TCP connection failed | my_HC
上記はサービスがダウンしているなどでTCPコネクションが確立できずダウン判定となった場合のEメールです。期待するコンテンツが返ってこなかった場合は以下のようにResponse body mismatch errorと記載されます。
2020-03-30 06:24:22 +0000 UTC | Down | Response body mismatch error | my_HC
以下のように、オリジンサーバが復旧した時もEメールが届きます。
2020-03-30 06:48:39 +0000 UTC | Up | my_HC
スタンドアロンヘルスチェック機能は、Pro、Business、Enterpriseプランに標準搭載される機能です。
パッシブオリジンモニタリング
スタンドアロンヘルスチェックは、それを機能させるためにCloudflareの設定やcgiの準備など、事前の設計・設定が必要なものです。 パッシブオリジンモニタリングは死活監視に関わる設定を全く必要とせずにオリジンサーバに問題が発生したことを検知することが出来ます。 Cloudflareはサイト訪問者からのリクエストを受信してオリジンサーバへ中継し、アプリケーションレベルゲートウェイとして機能しています。 そのため、オリジンサーバまで到達できないリクエストがあった場合にそのことを問題として検知することが出来ます。 このことがヘルスチェック関連のパラメータを与えずにオリジンサーバの問題を検知できる理由です。 オリジンサーバまで到達できないことが数分以上続くとEメールが送信されます。 この機能を使うには通知の設定のみ行う必要があります。
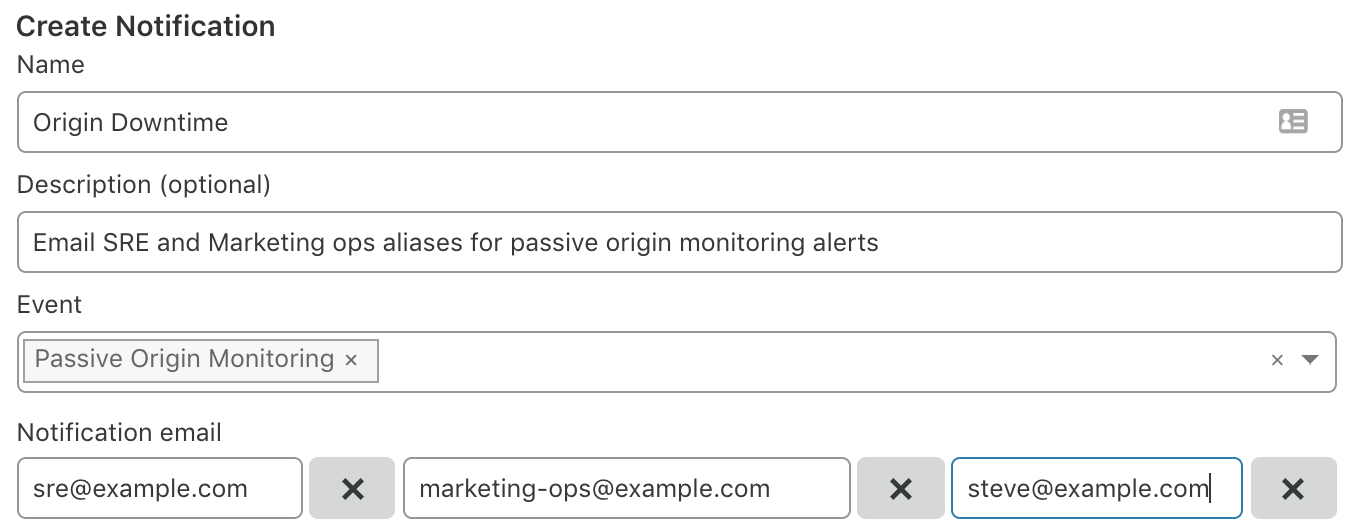
パッシブオリジンモニタリング機能は、Freeプランも含めた全てのプランで有効になっています。
ゼロダウンタイム・フェールオーバー
オリジンサーバのダウンを検知することも重要ですが、ダウンしてもサイトそのものはダウンしたように見せないのがベストです。 ゼロダウンタイム・フェールオーバーでは、リクエストがFailした場合、サイトを構成する別のオリジンサーバがある場合にそちらへリトライします。クライアントサイドのコネクションを保留した状態で別のオリジンサーバへの送信を試みる訳です。
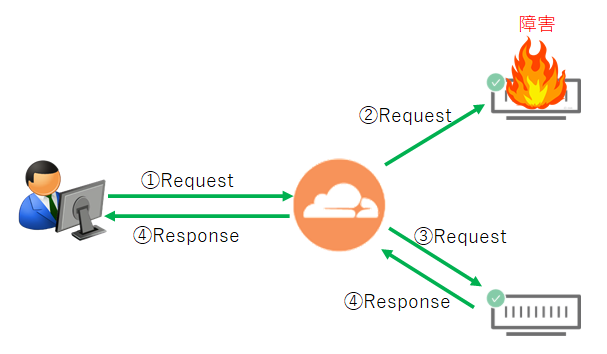
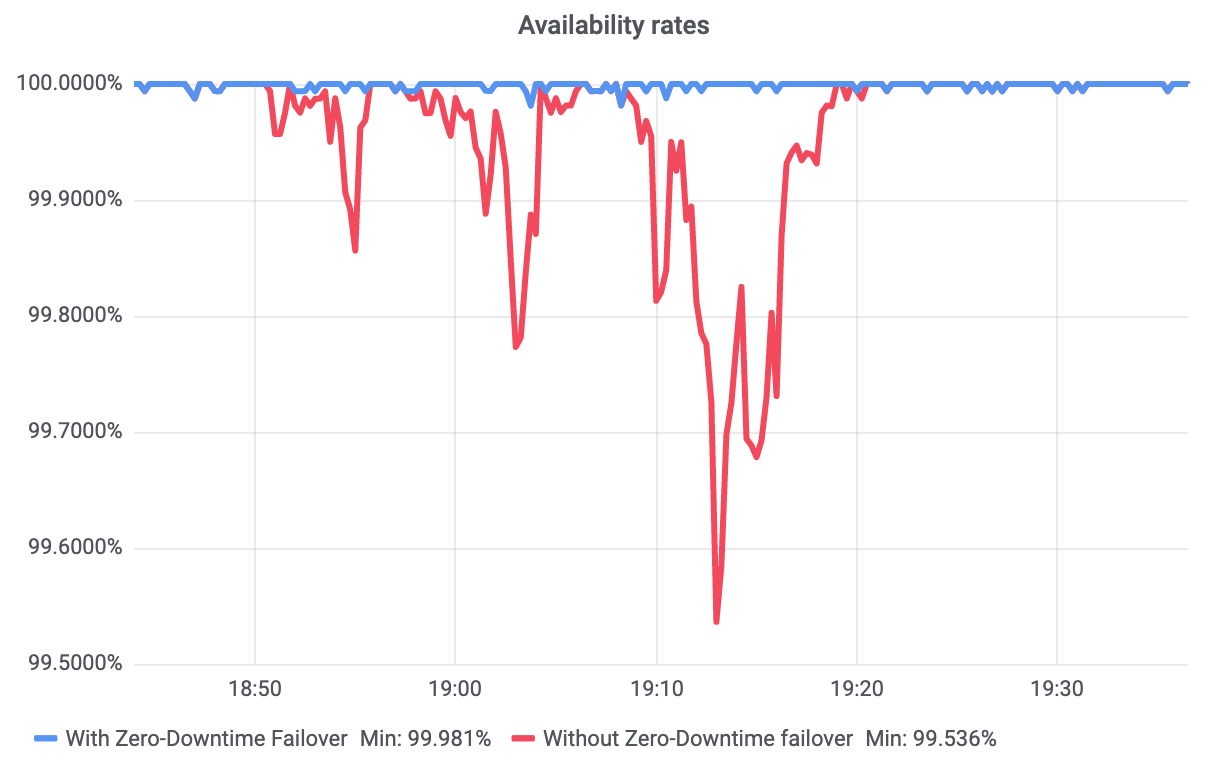
2つ目の振り先としては、DNS設定に登録された別のAレコード、ロードバランサー機能のPoolへ設定された別のオリジンサーバの何れかです。 ゼロダウンタイム・フェールオーバーは、ロードバランサー、スタンドアロンヘルスチェック、パッシブオリジンモニタリングと連携して機能し、Webサイトの稼働率を上げます。 以下の画像は実サイトで観測された稼働率です。ゼロダウンタイム・フェールオーバーがあれば、安定稼働できる様子が分かります。
TCPまたはTLSハンドシェイクのフェーズ中にFailしたリクエストのみを再試行することが出来ます。これにより、HTTPヘッダーとペイロードがまだ送信されていないことが保証されます。 ゼロダウンタイム・フェールオーバーは、Pro、Business、Enterpriseプランで標準搭載されている機能です。
まとめと考察
ヘルスチェックとロードバランサーは障害を回避する機能ですが、検知までに少々時間がかかり、取りこぼしのリクエストが発生します。ゼロダウンタイム・フェールオーバーは即座に機能しますが、リクエストをリトライするたびにレイテンシが追加されます。 両方を使うことで、トラブル発生からヘルスチェックで検知するまでのリクエストはゼロダウンタイム・フェールオーバーにより少しの遅延をもって正常応答し、ヘルスチェックで検知した以降は正常なサーバへのみトラフィックを割り振るのがベストです。

執筆者:角田 貴寛
三井情報株式会社
ソリューション技術本部 次世代基盤第二技術部 第一技術室
CISSP、CEH
現在、セキュリティ関連調査研究・教育業務に従事