成長する音声認識
はじめに

ここ数年音声認識を活用する企業や、導入を検討する企業が増えてきました。我々の身近なところにも、音声認識技術を使った製品やサービスが見られるようになり、音声認識は一般に普及したと言えるのではないでしょうか。
古くから使われている製品には、コールセンターで利用される電話の応対内容を文字に変換する製品や、会議中の会話を文字に変換し議事録にする議事録作成ソフトなどがありますが、これらは特定の業種や企業での利用にとどまり、一般的に馴染みがあるとは言い難いものでした。
近年はというと、店頭で訪れた客と会話するロボットや、スマートフォンに標準搭載された対話型AI機能など、本当に身近な技術になりました。これらは音声対話と呼ばれる音声認識+αの技術で、音声認識を活用したわかりやすい例だと思います。
今回は音声認識技術にフォーカスして歴史、近年の傾向など概要を説明したいと思います。
音声認識について
音声認識とは、人の発話した音をコンピュータに認識可能な情報に変換処理する技術です。朝、皆さんが「おはよう」と声を掛けられたら、「おはようと挨拶された」ことを理解すると思います。同じように「おはよう」を挨拶とコンピュータに認識させるのが音声認識の目的です。では、コンピュータが人間のように音を理解できるかというと、これはNoです。コンピュータは音を音としてとらえることが苦手です。そのため音を波形に変換し、その形を見て音を判断する手法が用いられます。
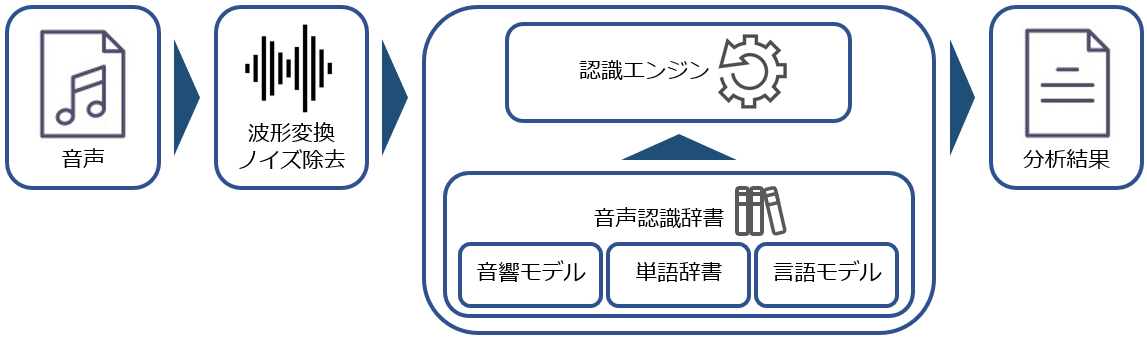
■音声認識概略
音声認識の歴史
音声認識の歴史は古く、私が調べる限りで、京都大学の研究者が1962年に単音認識に関する論文発表していることを確認しています。また初期の音声認識プロジェクトとして、1970年代初めにアメリカ国防高等研究計画局 (DARPA:Defense Advanced Research Projects Agency)が行ったプロジェクトが知られています。
何をもって研究の歴史とするかは議論の分かれるところでしょうが、50年以上の歴史がある研究テーマであることがわかります。
1970~80年代は主に研究がおこなわれており一般には普及していませんでした。1990年代にようやく音声認識を利用した製品が販売され一部で利用が開始されます。2011年にiPhone®にSiri®が標準搭載されると、多くの企業で製品やサービスが展開され身近なものとなりました。
音声認識のモデル
音声認識は音響モデルと言語モデルと呼ばれる2つのモデルを用いたパターンマッチングになっています。
1) 音響モデル
音響モデルとは、音素と音素の持つ特徴量を統計的なモデルで表したものです。音素とは言語が持つ音の最小単位で、母音と子音のようなものと考えていただければ良いです。日本語であれば、20数個あると言われています。
音響モデルは、音が入力されたとき、変換された波形の特徴をみてこの形は“あ(a)”、これは”い(i)”だというような判別を行うものです。
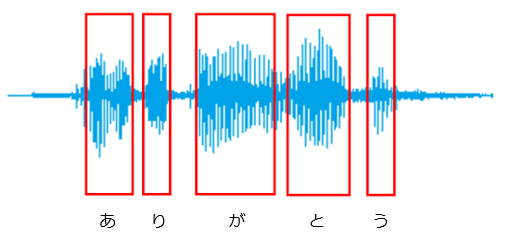
■音声の特徴量
2) 言語モデル
言語モデルとは、言語ごとの単語や文法の違いなどを、定式化または統計的に表現したモデルのことです。特に、音声認識では確率を用いた言語モデルを使用することが多く、確率的言語モデルと呼ばれることがあります。形態素解析により文章を名詞や助詞など単語単位に分割し、単語同士のつながりを確率で表現します。
言語モデルの学習には、およそ5年分の新聞など、大量の文章データを学習させる必要があります。
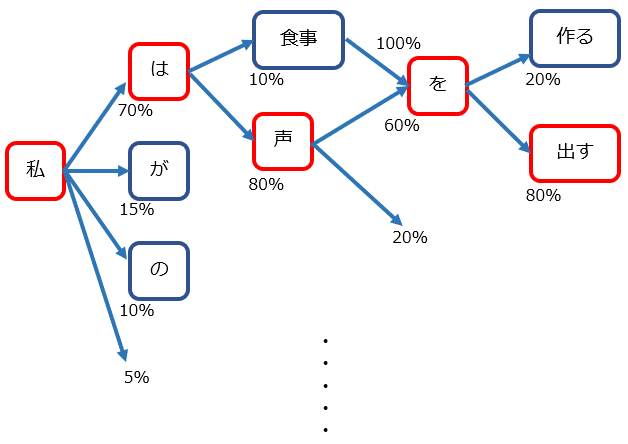
■言語の確率表現例
音声認識と深層学習の融合
先程説明したモデルは2000年代までの音声認識で広く使われていたモデルで、少し古い話になります。
今の主流は深層学習(ディープランニング)を利用したモデルになります。とはいえ、音声認識にニューラルネットワークを用いる研究は、実は1980年代に既に始まっていました。(深層学習は、ニューラルネットワークの中でも特に層数の多い(深い)ネットワークの学習のことを指します)当時は今より計算機の性能が低かったこと、扱えるデータ量が少なかったことから、従来手法にとって替わる成果につながらなかったというのが実態です。
方向転換の契機となった研究は2010年に発表されましたが、このときのモデルの原型も実は1994年に既に作られていたのです。
データ量の増加や計算機技術の発展にも後押しされ、現在では、電話など特定の状況下で95%の認識精度に達したと言われています。また、2019年の春には、Google AI Blog( https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html(2019-8-28))で、言語モデルを使用せずに従来手法より高い認識結果をだした研究が報告されており、未だ成長を続けているホットな分野といえます。
参考:篠田浩一「音声言語処理における深層学習:総説」日本音響学会誌、2017、73巻1号、pp25-30
まとめとMKIの取り組み
今回のコラムでは、最近特に身近に触れる機会が多くなった音声認識の仕組みや歴史についてご説明しました。
お読みいただいた通り未だ成長を続けているホットな分野です。MKIでも数年前からコンタクトセンター向けに音声認識ソリューションの販売をおこなっており、昨年度からは新たな取り組みとして音声認識を使った新しいサービスの検討を始めています。
執筆者

岩井川 裕
コア技術グループ ソリューション技術本部
クラウドソリューション部 第二技術室
通話録音システムの製品技術担当9年、音声認識の製品技術として2年従事
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。