未来を予測すること
弊社の汎用分析ツール、MKI分析予測ソリューション(以降、MKI分析予測)では、専門的な知識が無い方でも時系列データ分析が実施できます。
では、本ソリューションで実現する分析をデータ分析者が取り組むとどのようになるでしょうか。
本コラムでは、データ分析者が未来を予測する際に、どのようにアプローチしているのかをご紹介できればと思います。
導入
例えば、あなたの喉がカラカラに乾いていて、今すぐにでも自動販売機で飲み物が飲みたいとします。しかし、そんな時に限って自動販売機の飲料が売り切れていることがあります。
飲料が売り切れる前に補充してほしいと切に願うわけですが、負担を考えると補充業者の方は売り切れ直前で補充したいはずです。
そこで自動販売機の売上を予測し、売り切れ寸前の最適な時期に飲料を補充したいと補充業者の方が考えたと仮定して、販売数量予測の問題を考えてみたいと思います。
例えば、飲料補充の間隔が3日に1度であったとします。
とある自動販売機の某スポーツ飲料の売上は、例年であれば3日間で10本でした。しかし今年は酷暑の晴天続きで、3日間で20本も売れました。その次の3日間には地域のお祭りがあったため、さらに増えて35本となりました。このように売り上げの予測には様々な条件を勘案しなければなりません。
経験豊富な補充業者さんでないと売上の予測は難しいように感じます。
しかし、現在ではコンピュータを用いて、データの特徴や傾向を学習し、予測できるようになりました。そのプロセスは人間が学習しながら理解していくことと同様である為、機械学習と呼ばれます。
ということで、今回のコラムでは機械学習による、未来の予測についてご紹介したいと思います。
過去のデータから、未来を予測する
未来の予測には、過去のデータを利用します。
過去のデータから隠れている特徴や傾向を機械に学習させることができます。
学習した結果わかった「気温が高いと炭酸飲料がよく売れる」というような特徴をモデルと称します。モデルを数式で表現することで、過去のデータを入力すると未来の予測が計算されることになります。
モデルの例

機械学習の問題点
機械学習によりモデルが出来上がったとしましょう。
しかし、予測がうまくいかないケースがあります。
それは主に2つの原因に基づく可能性が考えられます。
- モデルの表現力が低いケース
モデル(数式)が単純すぎるケースです。
影響力の大きい要因が十分モデルに盛り込まれていないため、予測の精度が上がりません。
例えば、自動販売機の売上を夏は毎日50本、それ以外の季節は毎日15本というモデルでは、予測精度が低くなるであろうことは容易に想像がつきます。 - 過学習(オーバーフィッティング)を起こしているケース
過学習とは過去のデータに合いすぎて、未来のデータに当てはまらなくなることを指します。このような状況をモデルの一般性が失われているという意味で汎化性能が低いと言います。
何故、過学習が生じると汎化性能が低下するのでしょうか?
直観的には過去のデータを詳しく学習した方が予測の精度が向上するように感じますが…。
理由は過去の特殊な事例が、予測に大きな影響を与える一般的な要因としてモデルに組み込まれてしまう為です。
時として特定の飲料がテレビで特集を組まれたり、あるいは季節外れな気候になったりとイレギュラーな出来事が発生します。そのような出来事はあくまで一過性であって、定期的に発生するようなものではありません。その出来事を額面通り学習してしまうと予測精度が低くなってしまうのです。
可能な限り予測精度を上げたい。
しかし、データを学習し過ぎてしまうと過学習に陥り汎化性能が下がり、予測精度が下がってしまいます。
これが予測における最大のジレンマの1つなのです。
過学習を乗り越えるには
過学習を乗り越える為には、主に2つの対策があります。
1つは過学習を避けるための対策をモデルに組み込むことです。
モデルが細かくなり過ぎると予測精度が下がるようなペナルティをモデル自身の中に予め与えておくのです。
すると予測精度が高く、モデルが細かくなりすぎない“丁度いい塩梅”を見つけてくれます。
一般的にLASSOというアルゴリズムが広く用いられています。
2つ目はたくさんのモデルを作成し、その中から表現力を失わず
汎化性能を有したモデルを選択することです。
その中でも時系列データのモデルに適しているのがAICと呼ばれるモデル選択基準です。
AICは日本で生まれた手法で、AICのAは赤池弘次博士という提唱した方の名前を冠しています。
AICとは
AICはデータとモデルを与えるとモデル選択基準となる数値を返す関数です。AICの値が低ければ低いほど、良いモデル(≒予測精度が高い)であることを示します。
AICが相対的に高いモデルは、単純すぎるもしくは過学習を起こしているかのいずれかの可能性が高いわけですが、前者はともかく、なぜ未来のデータを見ずして過学習していることが判定できるのか? 大変不思議に思えますがそこが赤池博士の深謀遠慮なるところ、その難解な理論をご説明するには紙幅が全く足りませんので、またの機会に譲りたいと思います。
AICのシミュレーション
理論はともかく、実際にAICは未来のデータを用いることなく、過去のデータから最大の予測精度を持つモデルを選択できるのか、シミュレーションで確認してみましょう。
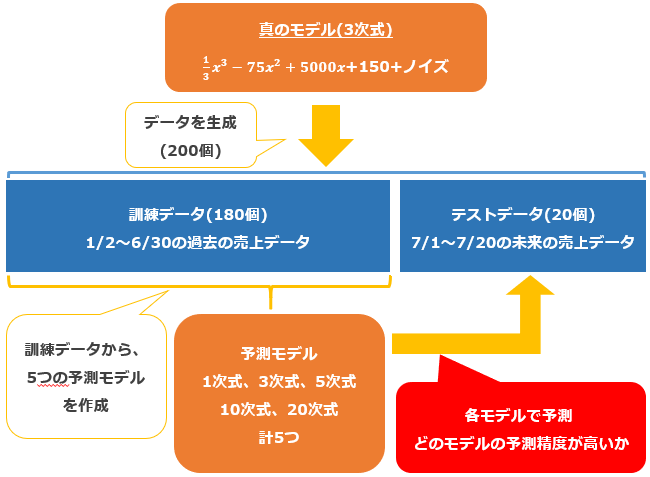
シミュレーションの概要は次の通りです。
自動販売機の売上データに見立てたデータを200個生成します。
データ生成には3次式にノイズを加えた下記の数式を“真のモデル”として利用します。
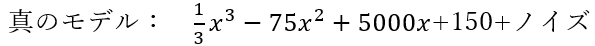
神様の気分でデータを創って、神様だけが知っているモデル(=真のモデル)を当ててみようという趣向です。
次に、真のモデルから生成された200個のデータの内、180個を過去のデータと見立てて学習モデルを作成します。学習モデルは1、3、5、10、20次式のそれぞれで作成します。
作成した学習モデルによって未来を予測するのですが、残った20個のデータを未来のデータと見立てて予測値と突き合わせることで、予測誤差(=モデルの優劣)を評価します。
以上が一連の流れですが、1度きりのシミュレーションでは「たまたま」予測精度が良い結果が得られる可能性がありますので、5,000回シミュレーションを繰り返し、予測誤差を平均した値で比較することにしましょう。
一方でAICは上記5,000回とは別に1回シミュレーションを実行し、その値から予測精度が高くなるモデルを判定することにします。
少々込み入ってきましたので、実例に置き換えて考えてみます。
今日は2018年6月30日。私たちは2018年1月2日から今日までの自動販売機売上データを持っており、翌7月1日~7月20日の売上を予測したいという問題設定です。
つまり200個の生成データを2018年1月2日~2018年7月20日までの自動販売機の売上とみなします。
内180個を学習データとしますので、2018年1月2日~2018年6月30日までのデータを元に学習モデルを作成します。その学習モデルから、2018年7月1日~2018年7月20日における売上の予測値を計算します。
機械学習の世界においては、モデルを作成するためのデータを「訓練データ」、モデルの性能を評価するためのデータを「テストデータ」と呼ぶ慣わしがありますので、本稿でも過去データ→訓練データ、未来データ→テストデータと言い換えることにします。
シミュレーション概要図
目的:訓練データの学習からテストデータの予測結果が良いモデルを選択する
実際に生成されたデータを確認してみましょう(5,000回のうちのある1回分)。
青が過去のデータ、赤が未来のデータです。
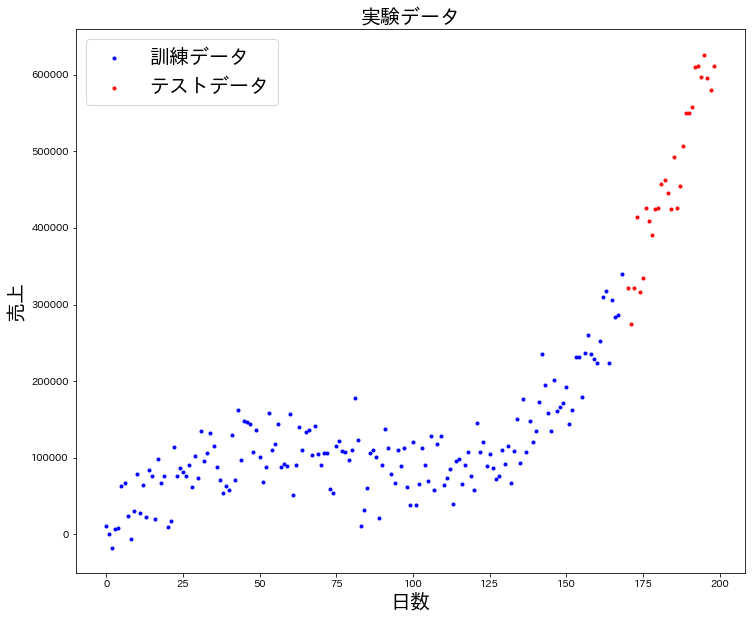
おおよその傾向は確認できますが、ややばらつきのあるデータとなっています。
自動販売機の売上に傾向はあるが、近くでお祭りがあったら売上が伸びる、雨だったら売れない等の特殊なケース(ノイズ)と似ていると言えるかもしれません。
では、訓練データによって作成されたモデルをグラフで確認しましょう。
データが多いと確認しづらいので、1、3、20次式のモデルのみピックアップして確認してみます。
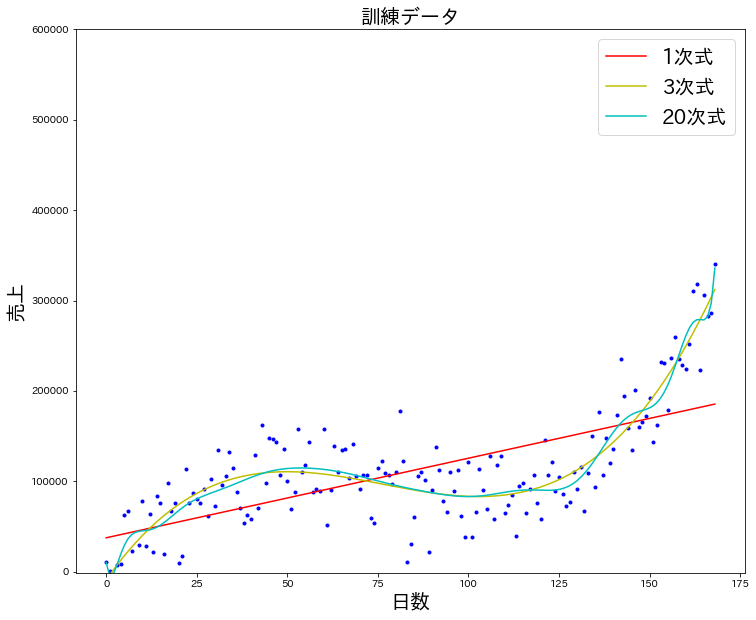
1次式は直線になってしまうので、あまり売上をうまく再現できているとは言えなさそうです。3次式と20次式の結果を比べると、後者の方が少々蛇行しており、散らばったデータを表現しよう!と試みているように感じます。
モデルの次数が大きいほど(モデルが複雑であるほど)
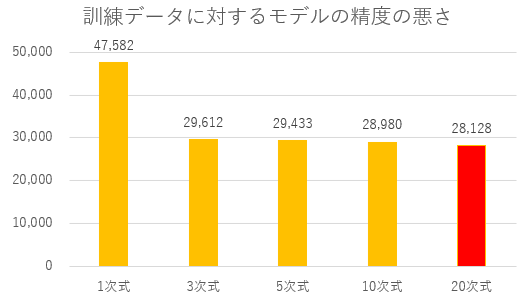
訓練データに対するモデルの精度は高くなることが確認できます。
訓練データに対するモデルの精度の悪さを表す値の平均は下記の通りでした。
| 1次式 | 3次式 | 5次式 | 10次式 | 20次式 | |
|---|---|---|---|---|---|
| 訓練データ | 47,582 | 29,612 | 29,433 | 28,980 | 28,128 |
では本丸の、テストデータに対するモデルの性能(予測誤差)を確認しましょう。
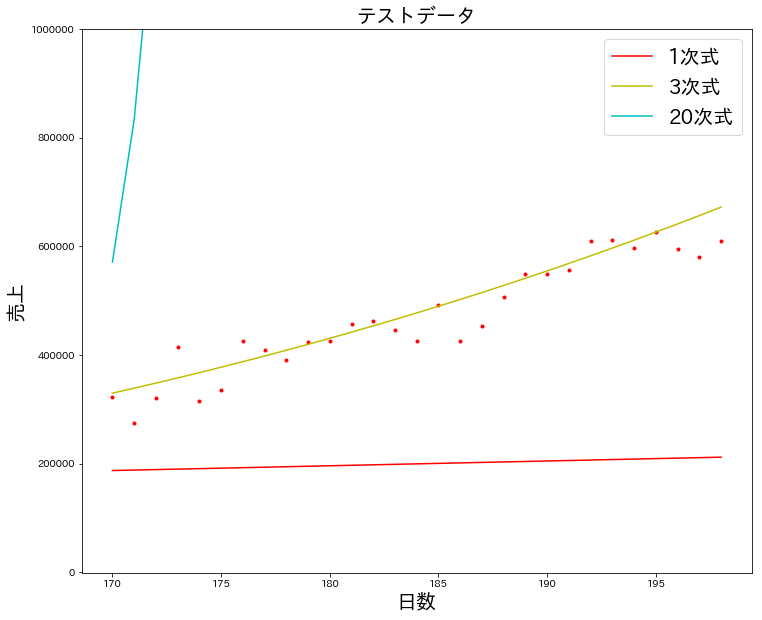
3次式の傾向は訓練データの結果とあまり変わりませんが、先ほど奮闘していた20次式は大きく外れてしまっています。これは訓練データにおいて最も良いモデルであった20次式は過学習してしまったのだと推測されます。
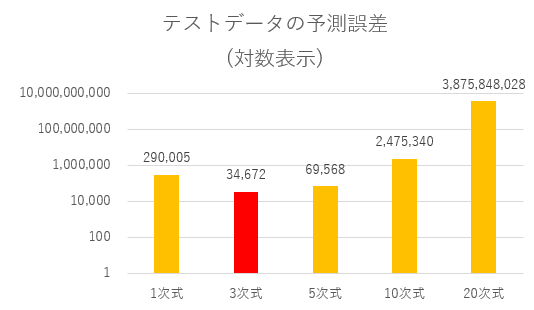
テストデータに対する予測誤差の平均は下記の通りです。
予測精度は20次式が最も悪く、3次式が最も良いことが確認できます。20次式は訓練データのノイズまで学習してしまった為、未知のデータに対する対応力(汎化性能)が落ちてしまったのです。
テストデータの予測誤差の平均
| 1次式 | 3次式 | 5次式 | 10次式 | 20次式 | |
|---|---|---|---|---|---|
| テストデータ | 290,005 | 34,672 | 69,568 | 2,475,340 | 3,875,848,028 |
ここで問題になるのは、未来のデータを使わないと良いモデルかどうか判断できない点です。
私たちが本当にやりたいことは未来のデータ自体を予測することですから、これはできない相談です。ところが、AICは未来のデータを見ずとも予測誤差の小さいモデルを教えてくれるというわけですから、訓練データとモデルからAICを計算してみましょう。モデルの作成同様5,000回のシミュレーションをしてAICの平均を取ることもできますが、現実に予測をする設定という意味で、1回きりの訓練データからモデルを作成しAICを計算した結果、以下のようになりました。
AICの結果
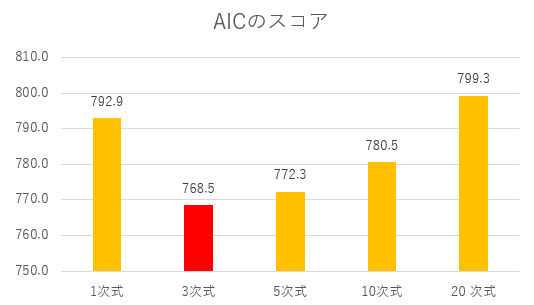
AICは数値が低いほど予測精度が高いことを示すので、未来のデータを何も見ていないにもかかわらず、汎化性能のもっとも高い3次式をピタリと言い当てることが出来ました!
弊社の分析ツール
MKI分析予測においてもAICのロジックを組み込んでいます。
今回のコラムでは詳細説明できませんでしたが、AIC以外にも予測精度を高めるロジック(例:P値を用いた検定や多重共線性のチェックなど)が組み込まれています。
MKI分析予測では、時系列データを読み込ませ、様々な分析モデルにて分析を予測します。その中で“丁度いい塩梅“のモデルを選択して、提示します。
MKI分析予測は汎用予測ツールですので、多くの時系列データを予測できます。
複雑な背景等知らずとも、予測から何らかのインサイトを得たい、
様々な予測をご自分で実施したいといった方に向けたソリューションです。
【画面イメージ】
まとめ
未来の予測についてという内容でお話させていただきましたが、いかがでしたでしょうか。
未来に思いを馳せるという夢のあるお話を、統計学、機械学習といったツールを用いると、このように解釈できるとご紹介できていれば、大変嬉しく思います。

平野 悠介
デジタルトランスフォーメーションセンター IoT技術部 イノベーション技術室
現在、主に小売関連のデータ分析に従事
中島 隆夫
バイオサイエンス部 バイオサイエンス室
現在、脂質同定システムLipid Searchおよび遺伝子解析サービスの開発に従事
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
本文および図表中では商標マークは明記していない場合があります。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。

