はじめに
今回のコラムでは、「ニューラルネットワーク」を使ったシンプルな分析例を紹介します。「ニューラルネットワーク」ないしは「人工知能」という言葉は、もはや多くのニュース記事で枕詞的に使用されているおかげか、我々が改めて紹介する必要もないほどに、すっかり普及してしまった感があります。しかしながらこのニューラルネットワーク、興味あるけど実装したことはない、理論から勉強しようとしたが挫折してしまった、APIやサービスを利用したことはあるけれど動きがイメージしきれてない、というような方も大勢いらっしゃるのではないでしょうか。我々はこの場をお借りして、そのような方々に対するニューラルネットワークのチュートリアルとして、「オートバイ」と「飛行機」を高精度に分類するような分析モデルを紹介します。
機械学習フレームワーク「ReNom」について
本コラムでは、GRID(グリッド)社が提供する機械学習フレームワークである「ReNom」を使用します。GRID社は、2009年に設立された日本のベンチャー企業です。『社会や人々の暮らしを支える「インフラ」にイノベーションを起こし、社会や生活「LIFE」をもっと豊かにしていきたい』という企業理念の下、ディープラーニングをはじめとした機械学習に関する様々な技術・アルゴリズムを活用することで、社会の様々な問題に対してチャレンジし続けています。GRID社のデータ分析に関する優れた技術、また、複雑に絡みあった問題へシンプルに相対する着眼点の良さはデータ分析業界内外から高く評価を受け、その存在感は指数関数的に拡大していっています。ReNomは、GRID社の技術の結晶ともいえる機械学習、特にニューラルネットワークを使用した分析モデルを、簡潔なコーディングで実装可能にする機械学習フレームワークです。
GRID社に関する詳しい情報は、GRID社WEBサイト
https://gridpredict.jp/をご参照ください。

※ReNomの名前は、多層化したニューラルネットワークにおいて重要な役割を担うと考えられている「繰り込み理論」(Renormalization)に由来します。
ReNomのインストール
ReNomは以下URLのガイダンスに従えば、ほんの数ステップでインストールすることが出来ます。今回、GPUを用いた高速な並列処理を実現するプラットフォームであるCUDAの設定は省略いたします。実行時間さえ考慮しなければ、CPUのみでの演算は可能なためです。
※ReNomのライセンスについて:2017/10時点では、学術目的や製品評価といった商用でない目的に限り、ReNomは無償で使用することが出来ます。
ReNomで実装!
さて、前置きはこれくらいにして、実際に、ニューラルネットワークモデルを用いた画像分類にチャレンジしてみましょう!
目的:
Caltech101(※1)から取得した「オートバイ」と「飛行機」の画像データを高精度に分類するモデルを作成します。
※1 画像分類のサンプルとしてカリフォルニア工科大学が提供しているデータセット。画像は101のカテゴリに分類され、1カテゴリにつき約40~800のイメージが提供されています。
https://data.caltech.edu/records/mzrjq-6wc02
方法
①画像認識の代表的なデータセットであるCaltech101をダウンロードし、「Motorbikes」と「Airplanes」フォルダを解析用のディレクトリにコピーします。今回は、image-binary-classification/に二つのディレクトリを置きます。
- mage-binary-classification/Motorbikes/
└798枚のオートバイの画像(jpg形式) - image-binary-classification/Airplanes/
└800枚の飛行機の画像(jpg形式)
「Motorbikes」と「Airplanes」内のデータの実態は、jpg形式のカラー画像となります。中身をチェックすると、画像自体の大きさ、対象物の色は勿論のこと、背景画像の有無、対象物の向きなどがバラバラな状態になっているようです。本当に分類できるかな、大丈夫かなという気がしますが、ご安心ください。ニューラルネットワークの一つの技法であるCNN(畳み込みニューラルネットワーク)はこの問題を鮮やかにクリアしてしまいます!
仮に、これらをニューラルネットワーク以外の手法で分類しようとすれば、「オートバイといえば曲がったハンドルとか大きなタイヤとか」「飛行機といえばプロペラとか羽とか」など、二つのオブジェクトを特徴づけるような「モノ」「コト」を我々が明示的に与える作業が必要になるかもしれません。これは非常に難しい作業で、飛行機にだってタイヤはあるし、プロペラがないものもあります。角度によってはオートバイのハンドルは曲がっていないかもしれません。ニューラルネットワークはこの作業をスキップ出来るだけでも非常に有効な手段といえます。
②続いてReNomでのコーディングに移ります。Jupyter Notebook上でPython3を使用して実装しました。
まず、今回の分析で使用するライブラリを読み込みます。すべて一般的なライブラリです。
import renom as rm
from renom.utility.distributor import ImageClassificationDistributor
from renom.utility.distributor.imageloader import ImageLoader
from renom.utility.image import *
from renom.optimizer import Sgd, Adam
from renom.cuda.cuda
import set_cuda_active
import matplotlib.pyplot as plt
import numpy as np
import math
import os
from PIL import Image
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import confusion_matrix, classification_report
from
sklearn.model_selection import train_test_split
③解析する上で便利な関数を定義します。
画像分類のためのデータを読み込むための関数
def load_for_classification(path):
class_list = os.listdir(path)
onehot_vectors = []
for i in range(len(class_list)):
temp = [0] * len(class_list)
temp[i] = 1
onehot_vectors.append(temp)
X_list = []
y_list = []
for classname
in class_list:
imglist = os.listdir(path + classname)
for filename in imglist:
filepath = path + classname + "/" + filename
X_list.append(filepath)
onehot = onehot_vectors[class_list.index(classname)]
y_list.append(onehot)
return X_list, y_list, class_list
④画像データのパスとラベルを取得します。
この操作により、X_listには、各画像のパス、Y_listには、各画像のラベル(オートバイか飛行機かなど)の情報が格納されます。
path = "[画像を置いたパスを指定、本解析では、image-binary-classification/]"
X_list, Y_list, class_list = load_for_classification(path)
⑤画像の読み込みとリサイズを行います。
X_listに格納されたパスを利用して、画像をRGB形式で読み込みます。さらに、画像の一辺の長さを32ピクセルに揃える前処理を行います。最後に、各ピクセルの数値が0~1に収まるようにします。本コラムで構築するニューラルネットワークのモデルは、入力層のユニットが固定値となるので、各画像のサイズを揃える必要があるのです。
x_size=32
y_size=32
channel=3
# 元となる画像の読み込み
X_tmp = np.empty((0,x_size*y_size*channel), int)
Y_tmp = []
for i in range(len(X_list)):
img = Image.open(X_list[i]).convert('RGB')
img = img.resize((x_size,y_size))
img = np.asarray(img)
img = img / 255.
img = np.array([list(img.flatten())])
X_tmp
= np.append(X_tmp, img, axis=0)
Y_tmp = np.array(Y_list)
⑥ReNomに読み込ませるためのデータ加工を行います。まず、データセットを学習用のセットと評価用のセットに分割します。なぜ、評価用のセットを前もって確保しておくかというと、作成した分類モデルが、新たな画像に対してどれほどの分類能力を持つかどうかを定量的に評価するためです。また、今回は畳み込みニューラルネットワークを扱いますので、データセットをNCHW形式のテンソルデータに変更します。ここではN:バッチサイズ(一度の計算でまとめて処理するデータ数)、C:チャネル数(異なる観点で画像の特徴を捉える。’R’ 、’G’ 、’B’形式なので3)、H:画像の縦幅、W:画像の横幅、となります。
test_size = 0.2
X_train, X_test, y_train, y_test = train_test_split(X_tmp, Y_tmp, test_size=test_size)
X_train = X_train[0:int(len(X_tmp) * (1 - test_size))]
y_train = y_train[0:int(len(X_tmp) * (1 - test_size))]
X_test = X_test[0:int(len(X_tmp) * test_size)]
y_test = y_test[0:int(len(X_tmp) * test_size)]
X_train = X_train.reshape(-1, x_size, y_size, channel)
X_train = X_train.transpose(0,3,1,2)
labels_train = LabelBinarizer().fit_transform(y_train).astype(np.float32)
X_test = X_test.reshape(-1, x_size, y_size, channel)
X_test = X_test.transpose(0,3,1,2)
labels_test = LabelBinarizer().fit_transform(y_test).astype(np.float32)
N = len(X_train)
⑦ニューラルネットワークの定義を行います。数千個程度のデータを2つのクラスに分類するという比較的シンプルな問題となりますので、過学習を引き起こさないようにするために、下記に示す通り層の浅いネットワークにしました。
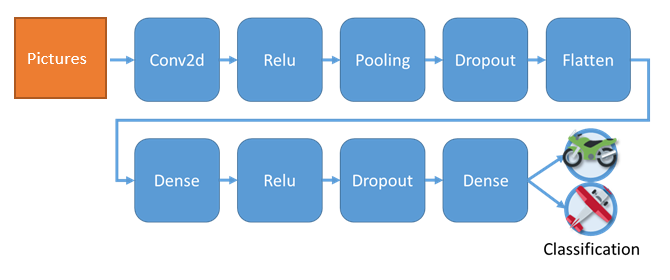
Figure 1 本解析でのネットワーク
上図ネットワークはReNomの「Sequential」という定義方法を用いると、上から書き下すように簡便に記述することが出来ます。
sequential = rm.Sequential([
rm.Conv2d(channel=32),
rm.Relu(),
rm.MaxPool2d(filter=2, stride=2),
rm.Dropout(dropout_ratio=0.25),
rm.Flatten(),
rm.Dense(256),
rm.Relu(),
rm.Dropout(dropout_ratio=0.5),
rm.Dense(2),
])
⑧ネットワークとオプティマイザー(各ユニットの重みを最適化していく手順)をインスタンス化します。Adamは2015年に提案された新しい最適化手法ですが、ReNomでは、インスタンス化するだけで簡単に利用することが可能です。
network = sequential
optimizer = Adam()
⑨ここまで、データの準備から始まり、ネットワークの定義や、最適化手法の選択など様々なことを実施してきました。最後にこれらを学習ループの中に統合し、画像分類のスクリプトを完成させます。ニューラルネットワークの学習(トレーニングデータになるべく適合するように重みとバイアスを調整させていくこと)は、以下の手順によって行います。
(1)まずトレーニングセットからバッチ数個だけデータをランダムに取り出します。
(2)次にフォワードの処理として、選んだデータをニューラルネットワークに流し込み、損失関数(=ニューラルネットワークの性能の悪さの指標。今回はCross Entropy Errorを使用)を計算します。
(3)続いて、各重みパラメータに関する損失関数の勾配を求め、各パラメータについてどの程度改善の余地がありそうかを計算します。
(4)更に(1)(2)(3)の工程を、トレーニングセットを使い切るまで行っていきます。
(5)ここで得られたバイアスと重みとテストセットのデータを使って、再度損失関数を計算します。
最後に、(1)~(5)の工程をepochの数だけ、繰り返し行います。
# ハイパーパラメータ
batch = 100
epoch = 10
learning_curve = []
test_learning_curve = []
for i in range(epoch):
perm = np.random.permutation(N)
loss = 0
for j in range(0, N // batch):
train_batch = X_train[perm[j * batch:(j + 1) * batch]]
responce_batch
=labels_train[perm[j * batch:(j + 1) * batch]]
# ロス関数
network.set_models(inference=False)
with network.train():
l = rm.softmax_cross_entropy(network(train_batch), responce_batch)
# バックプロパゲーション
grad = l.grad()
# 重みの更新
grad.update(optimizer)
loss += l.as_ndarray()
train_loss = loss / (N // batch)
# モデルの評価
test_loss = 0
M = len(X_test)
network.set_models(inference=True)
for j in range(M//batch):
test_batch = X_test[j * batch:(j + 1) * batch]
test_label_batch = labels_test[j * batch:(j + 1) * batch]
#print(test_label_batch)
prediction
= network(test_batch)
test_loss += rm.softmax_cross_entropy(prediction, test_label_batch).as_ndarray()
test_loss /= (j+1)
test_learning_curve.append(test_loss)
learning_curve.append(train_loss)
print("epoch %03d train_loss:%f test_loss:%f"%(i, train_loss, test_loss))
⑩最後にどのように学習が進んでいったか、またモデルの分類性能はどれ程のものかを評価します。前者は学習曲線で、後者は混合行列によって行います。両者は下記コードによって実現します。
network.set_models(inference=True)
predictions = np.argmax(network(X_test).as_ndarray(), axis=1)
# Confusion matrix and classification report.
test_seikai_label = (np.argmax(y_test,axis = 1) ).reshape(-1,1)
print(confusion_matrix(test_seikai_label,
predictions))
print(classification_report(test_seikai_label, predictions))
# Learning curve.
plt.plot(learning_curve, linewidth=3, label="train")
plt.plot(test_learning_curve, linewidth=3, label="test")
plt.title("Learning curve")
plt.ylabel("error")
plt.xlabel("epoch")
plt.legend()
plt.grid()
plt.show()
結果
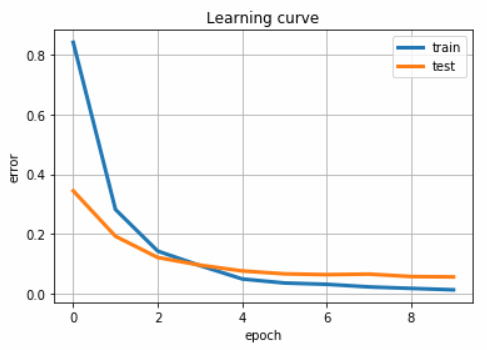
学習曲線
学習曲線の図は、横軸がepoch数を示し、縦軸がCross Entropy Errorの値を示します。参照すると、トレーニングセット、テストセットともに、学習する毎にCross Entropy Errorの値が低減していき、精度が高まっていることが推測できます。
混同行列
混同行列を用いて予測結果の精度を評価します。混同行列は予測の間違い、正解のみに注目するだけでなく、どう間違えたのかについても考える評価方法です。今回の例で言うと、「本当はオートバイのはずなのに、飛行機に分類してしまった」もしくはその逆、「飛行機のはずなのに、オートバイに分類してしまった」の二つが間違いとして考えられます。そして、混同行列を一つの数値で評価するのが、F1スコアとなります。F1スコアは精度と再現率の調和平均で定義されます。今回はそのF1が、0.98になる(最大値は1)という優れた分類器を作成することができました!
考察
不正解のラベルに分類されてしまった画像はどのようなものなのでしょうか。
画像はいずれもモザイクがかかったような状態で、なんとか判別できるものもありますが、正直人間でも自信をもって答えられないものばかりでした。このように畳み込みニューラルネットワークは、人間の分類能力にも負けずとも劣らないような性能を持つことが示唆されました。
最後に
今回は「オートバイ」と「飛行機」を分類するニューラルネットワークのモデルを作成するというものでしたが、画像を変えるだけで、「もりそば」と「ざるそば」を分類するモデルを簡単に作成することが出来ますし、「おすぎ」と「ピーコ」も同様に学習させられます。是非みなさまも画像を用意して遊んでみてください。我々はReNomを用いることで、アイデアを瞬時のうちに形にすることが出来ました。さらに、ReNomは拡張性が非常に高いフレームワークでもあります。今後は、リアルタイムで画像認識をする「YOLOv2」や機械翻訳等々に用いられている「Seq2Seq」といった、今をときめくアルゴリズムもReNom上に追加機能として実装していき、その面白さを余すところなく体験していきたいと思います。

データ分析チーム(担当:黒澤、大内、水谷)
デジタルトランスフォーメーションセンター IoT技術部 イノベーション技術室
現在、業界業態問わずデータ分析関連の案件を手掛ける分析チーム(の一部メンバー)。
新技術・新製品の検証や導入も積極的に行っている。
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。 本文および図表中では商標マークは明記していない場合があります。 当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。 また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。

