はじめに
ビジネスでデータを活用することは、良い判断をするための大切な手段です。しかし、たくさんのデータを集めただけでは、たとえばキャンペーンが本当に効果的だったのかどうかを判断するのは難しいこともあります。
そこで、この記事では、原因と結果の関係を正しく理解する「因果推論」について、ご説明します。ランダムにグループを分けて効果を比べる方法や、既にあるデータを使って工夫する方法などを通じ、それぞれの施策に対する効果を正しく見極めるにはどのような考え方や分析が必要かをご紹介します。
ビジネスにおけるデータ分析活用の難しさ
ビジネスにおいてデータ分析が重要と言われていますが、なかなか進んでいないというお話も伺います。データを投入して機械学習を実施し結果までは出せるものの、その結果から何を判断すればよいのか、どう行動すればよいのかわからなかったという体験は少なからずあるのではないでしょうか。失敗例を見ると、データやAIの活用が主になり、何をするべきかの目的がおろそかになっていることが多いようです。
成功例を見ると、まずビジネス上の目的があり、それに対する判断材料を提供するような分析結果が得られるよう、計画的にデータ分析を実施していることがわかります。
意思決定のためのデータ分析
ビジネス上の目的があり、それを満たせない現状を克服するために施策を打ちます。その判断材料を出す手段としてデータ分析があります。つまり、ビジネス上の意思決定のためにデータ分析を行います。
また、当社の別コラム「データサイエンスの世界へようこそ」では、データ分析を行うためのデータサイエンスと意思決定がもともと密接な関係であることを示しています。そして、相関関係と因果関係を混同してはならないこと、通常の機械学習では相関関係しか扱えず、統計的因果推論が必要なことを伝えています。
相関だけを捉えればよいデータ分析もあります(画像やテキストの分類で省力化を目指すなど)が、施策の効果の判断などとなると因果関係を正しくとらえる因果推論が必要となってきます。
因果推論とは
因果推論とは、ある対象に何らかの手を打った(介入や処置と呼ばれます)場合に、その効果がどれくらいあるかを推定することです。基本的には手を打ったときと手を打っていないときの結果を比較すれば、その効果(因果効果)がわかります。
例えば以下の「クーポンを配布してどれだけ購入が増えるか」の例であれば、クーポンを受け取った人と受け取っていない人がどれだけ購入したかを比較すれば、一見よさそうです。
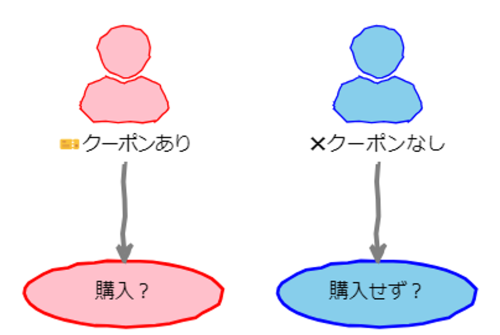
しかし、ここに厄介な問題として「交絡」と「反事実」があります。
原因と結果に影響を与える「交絡」
クーポンを受け取った人は、クーポンを受け取ったことが原因で購入したのでしょうか。顧客がクーポンを受け取ったことと、もともとその商品への強い購買意欲があることのどちらが購入につながったのかは区別をする必要があります。
もしかしたら、もともとその商品の購入意思があり、自分からクーポンを受け取って購入したのかもしれません。また、クーポンを受け取っていない人がクーポンを受け取ったら購入したでしょうか?もともとその商品に関心がなく、クーポンを受け取らなかったのかもしれません。そして、クーポンを受け取っても購入しなかったかもしれません。このままではクーポンが原因なのか、その商品への関心が原因なのかがわかりません。
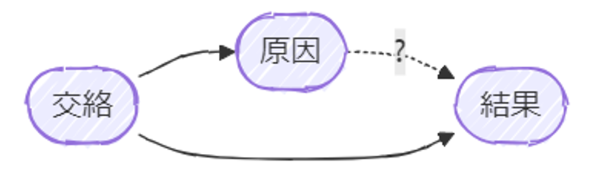
ここに交絡が潜んでいます。交絡とは原因と結果の両方に影響を与える因子のことです。「原因」と「結果」となる因子があると一見、「原因→結果」の関係がありそうに見えますが、「交絡」は「原因」と「結果」の双方に影響しています。つまり、「原因→結果」の因果関係があるのではなく、「交絡→原因・結果」の関係を見ていることになります。
クーポン配布の例で言えば
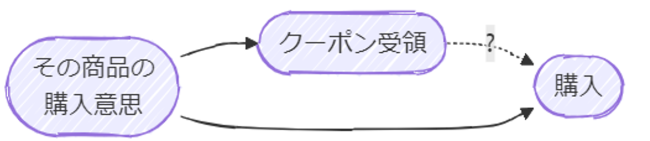
となり、
- その商品の購入意思があることが原因でクーポンを受け取り、購入もした
- その商品の購入意思がないことが原因でクーポンを受け取らず、購入もしなかった
ことが考えられ、こうなるとクーポンは購入に影響がなく、その商品の購入意思によるということになってしまいます。
このような簡単な例であれば、交絡を見つけ出して対処する方法もありますが、実際のビジネス例では関係する変数が多くなり、交絡をきちんと見つけ出すのが非常に困難です。
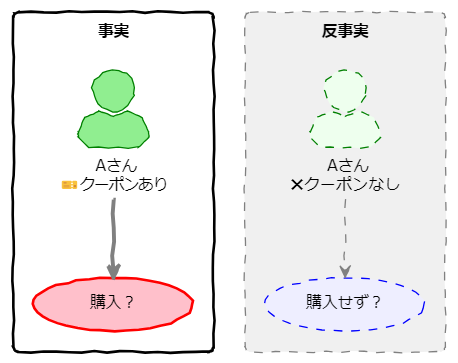
事実と「反事実」を比較したいができない
同一人物であれば購入意思も同じなので交絡の影響がなくなります。では、Aさんにクーポンを渡したときの購入有無と、同じくAさんにクーポンを渡さなかったときの購入有無を比較すればよいですが、この状態は存在しません。
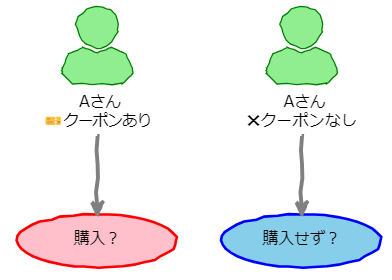
例えばAさんにクーポンを渡していれば、クーポンのないAさんは存在しません。これを事実と反事実と呼びます。反事実とは施策の有無が逆であり、存在しない事実のことです。逆にAさんにクーポンを渡していなければ、クーポンを渡したAさんは存在せず事実と反事実が逆になりますが、事実と反事実は同時には存在しません。
最初にAさんにクーポンを渡し、一定期間後Aさんにクーポンを渡さず、といったようにタイミングをずらすことは一見可能に見えますが、ではその時のAさんの購入意思が異なるなどこれまた正確な比較ではありません。
「交絡」と「反事実」を乗り越えるための「実験」と「準実験」
打ち手の効果を知りたいところに「交絡」と「反事実」が立ちはだかります。通常の機械学習ではこれらに対応していません(新しい技術として通常の機械学習とは異なる「機械学習による因果推論」は別途あります)。これには統計的因果推論という分析手法が必要です。考え方としては実験と準実験があります。
実験
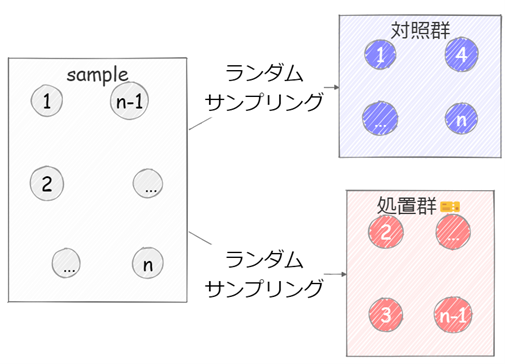
実験の手法としてはランダム化比較試験(RCT)があります。施策の効果を見たいターゲット(クーポン配布の例で言えば顧客)をランダムに、何もしないグループ(対照群)と、打ち手を実施する(クーポン配布の例ではクーポンを配布する)グループ(処置群)に分けます。そうすることで、打ち手の有無以外のターゲットごとの条件が均せる(これを「ランダム割り当て」と言います)ため、
- いろいろな交絡の可能性はあるものの交絡の影響を均せる(クーポン配布の例で言えば、その商品の購入意思が均せるということ)
- 正確な反事実ではないけれども、処置群を事実、対照群を反事実として事実-反事実の比較ができる
ようになります。
こうして対照群と処置群の値を比較すればその差が因果効果となり、因果推論ができるというわけです。
この手法は交絡をかなり均せるため、精度のよい因果効果推論となりますが、新たに実験をする必要があるためコストが掛かります。
とは言え、医学や創薬などの命にかかわるような分野では高い精度が求められますので、コストを掛けてこの手法が用いられています。
また、Webサイトのデザイン比較などではユーザーごとにランダムに画面を切り替えるだけで比較的低コストで実験できるので、この手法がよく用いられます。別名A/Bテストとも呼ばれます。
準実験
こちらは既に取得済みのデータを用いて、あたかも実験したかのような状況をつくりだすというものです。回帰不連続デザイン(RDD)、傾向スコアマッチング(PSM)、操作変数法(IV)、差の差分析(DiD)、などが代表手法です。
ここでは傾向スコアマッチングを紹介します。
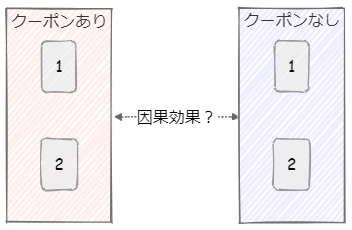
クーポン配布の例では購入意思によりクーポンの受け取りやすさに差があるのではないか、それが交絡となって因果関係を正確に捉えられないというお話をしました。であればそのクーポンの受け取りやすさをスコア化して、同じスコアの人で比較すればよいのではないかという考え方です。
まず、元のデータのままで比較しようとした場合、「クーポンあり」の側は購入意思が高めな方、つまり積極的にクーポンを受け取ろうというクーポンの受け取りへの意志が高い方が多めと考えるのが妥当です。
逆に、「クーポンなし」の側は購入意思が低めな方、つまり積極的にクーポンを受け取ろうとしない方が多めと考えられます。
すでにお話ししている通り、このままではクーポン受け取りの影響によりクーポンの効果が正確に測れません。
そこで傾向スコアマッチングを導入します。この手法はマーケティング分析などでよく用いられます。
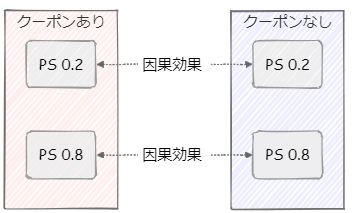
まず、個々の顧客の属性や購買履歴等からクーポンの受け取りやすさを推定して0~1のスコア化をします。これを傾向スコア(Propensity Score、以下PSスコア)と言います。当然ながらクーポンありの方はPSスコアが高い方が多めとなり、クーポンなしの方はこのPSスコアが低い方が多めとなります。ただ、PSスコアが低くてもクーポンをもらい、PSスコアが高くてもクーポンをもらわない顧客も少ないながら存在します。
そこでPSスコアが同じ顧客の購買有無を比較すれば、購入意思からくるクーポン受け取りの影響は避けられるだろうという考え方です。疑似的に交絡の影響を排除し、反事実を作り出しているといえます。
傾向スコアマッチングをはじめ準実験手法は、すでに取得済みのデータを使うことができ、新たに実験をする必要がないため低コストで行えます。ただ、交絡の影響を排除しきれず、適切な反事実となるかは限界があり(傾向スコアマッチングであれば、傾向スコアの精度が低ければ誤ったマッチングをしていることになる)、精度はランダム化比較試験よりも低くなることが多いです。ツールやライブラリで簡単に実行出来るので、誤った分析をしてしまわないよう注意が必要です。
その他、最近では因果関係を考慮した機械学習を用いて、より精度を高めようという技術も進んでいます。
まとめ
ここまで、ビジネスでは意思決定が重要であり、それを目的としたデータ分析には因果推論が必要となることを見てきました。商品の発注数を決めるために需要予測を行うなど、必ずしも因果推論がなくとも意思決定に役立つデータ分析手法もあります。ただ、ある状況に対して何らかの打ち手が複数あり、それらのうち一番費用対効果の高い打ち手を採用したい、というケースでは因果推論がほぼ必須となります。
正直難しい考え方ではありますが、ある分析結果が示されたときに皆さんも、
- 「原因と結果に影響しているような要素はないか?」(交絡の影響を確認する)
- 「事実と反事実(に相当するもの)を正しく比較しているか?」(事実-反事実の比較となっているか確認する)
を今後意識していくと、意思決定のためのデータ分析により近づけると思います。
今回は施策ごとの効果を知る方法でしたが、次回コラムでは「顧客ごとの施策を最適化する高度な因果推論」についてお話したいと思います。

青木
イノベーション推進部 第一技術室
データサイエンス関連の技術調査に従事




三井情報グループは、三井情報グループと社会が共に持続的に成⻑するために、優先的に取り組む重要課題をマテリアリティとして特定します。本取組は、4つのマテリアリティの中でも特に「情報社会の『その先』をつくる」「ナレッジで豊かな明日(us&earth)をつくる」の実現に資する活動です。
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
本文および図表中では商標マークは明記していない場合があります。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。



