はじめに
近年、ビジネスではすべての顧客に同じ施策を提供するのではなく、一人ひとりに合わせた対応が求められています。従来の統計的因果推論と呼ばれる手法(前回の記事「ビジネスの意思決定に必要な因果推論」でお話しした「傾向スコアマッチング」など)では、一つの施策に対して、顧客全体の平均的な効果しか把握できず、どの顧客にどの施策が響くのかを見極めるのは難しいものでした。
そこで今回ご紹介するのが、反実仮想機械学習という手法です。この方法は、過去のログデータを使い、施策を実施しなかった場合の結果(反事実)を予測することで、実際の効果と比較し、個々の顧客に対する施策効果を推定します。本記事では、この新しいアプローチの基本的な考え方とメリットを解説していきます。
施策ごとの効果から顧客ごとの施策効果へ
前回の記事「ビジネスの意思決定に必要な因果推論」で触れた「最近では因果関係を考慮した機械学習を用いて、より精度を高めようという技術も進んでいます。」についてお話しします。
因果関係を考慮した機械学習にもいろいろありますが、今回は反実仮想機械学習をご紹介します。まず、因果推論の難しさは、存在しない反事実と比較しないと因果効果の推定が出来ないことでした。クーポン配布の例では、Aさんにクーポンを配布した場合にクーポンを配布していないAさんは存在しません。また、単にクーポンを配布していないBさんの購入有無との比較では「交絡」などの問題で正しい効果推定ができないというお話をしました。
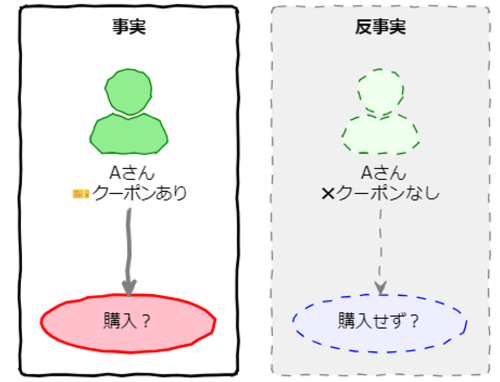
そのため、従来の統計的因果推論では、「実験」や「準実験」の手法で効果推定をしていました。今回お話しする反実仮想機械学習はこの反事実を予測してしまおうというものです。
従来の統計的因果推論との違いは、
- 統計的因果推論
- 本来は事実と反事実を比較して効果の推定を行いたいが反事実は存在しないため、「実験」手法(ランダム化比較試験)、「準実験」手法(傾向スコアマッチングなど)により、条件の近いサンプルの施策の有無により仮想的に「事実」と「反事実」の比較を行う。
- 本来は事実と反事実を比較して効果の推定を行いたいが反事実は存在しないため、「実験」手法(ランダム化比較試験)、「準実験」手法(傾向スコアマッチングなど)により、条件の近いサンプルの施策の有無により仮想的に「事実」と「反事実」の比較を行う。
- 反実仮想機械学習
- ログデータなどからサンプル毎に存在しない「反事実」を予測し、事実と「反事実」の比較を行う。
- Aさんと類似の顧客属性かつ購買履歴の顧客のデータを元に、Aさんがクーポンを受け取っていなかったときの行動(購入したのかしなかったのか)を予測する。
- Aさんの「反事実」を予測で作り出すことになります。「事実」としてクーポンを受け取ったときに購入していた場合、クーポンを受け取っていないという「反事実」での行動を予測します。
- 「反事実」のときも購入していたと予測されれば、クーポンの有無に関係なく購入していたと考えられます。つまり、クーポンの効果はないだろうと判断できます。
- 「反事実」のときは購入していないと予測されれば、クーポンがあったから購入したのだろうと考えられます。つまり、クーポンの効果はあるだろうと判断できます。
- ログデータなどからサンプル毎に存在しない「反事実」を予測し、事実と「反事実」の比較を行う。
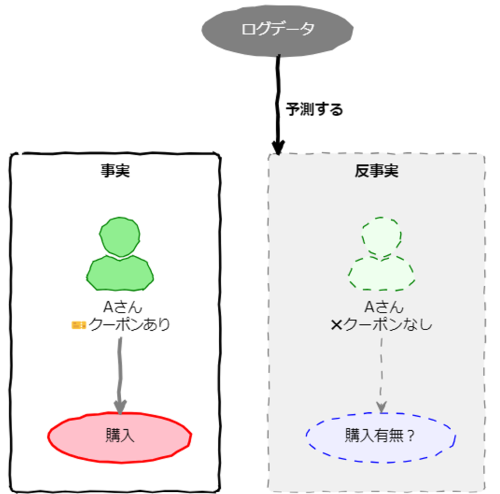
この手法を精度よく行うためには、Aさんに類似、またBさんに類似の顧客属性や購買履歴があるようなデータが大量に必要となります。また、Aさんに類似とは何かという指標をうまく見つける必要があります。
ただ、それらの課題クリアできると、この手法の利点として、
- 予測ではあるが事実と「反事実」の比較が直接できる
- 同じサンプル(顧客)を比較するので「交絡」の問題が生じない
があります。さらに、従来の統計的因果推論では施策毎の効果は分かりますが、顧客一人ひとりの効果は分かりませんでした。この反実仮想機械学習の手法によると、顧客一人ひとりに対して、Aさんの場合はクーポン付与の効果がどの程度か、またBさんの場合はどのような効果が期待できるかが個別に推定できるようになります。
リアルの店舗では顧客一人ひとりに個別にクーポン有無や施策を分けることは困難ですが、Web上の販売やサービス提供であればこれが可能となります。
最適な施策(方策)とは
個々の顧客に対して、クーポンなどの施策の効果が推定できることがわかりました。では、Webサイトのサービスでは、どういう施策を打てば、利益が最大化するのでしょうか。クーポン配布有無、またその内容(割引率なのか、おまけをつけるのか)、ポイント付与がよいのか、お薦めの改善がよいのか、利用シーンが分かるような追加コンテンツの充実がよいのか……。
ここで、オフ方策評価、オフ方策学習という手法があります。オフとは、過去に実施した施策の結果として得られたログデータを用いるという意味です。方策とは何らかの施策などのことです。
- オフ方策評価
- ログデータなどを用いてある方策の効果(利益やクリック率など)を評価すること
- オフ方策学習
- ログデータなどを用いて学習し、最適な方策をみつけること
となっています。
Web上の買い物サイトや動画サイト、ゲームサイトで、「通常のキャンペーンとは違うクーポンがたまに出るな」と思ったときは、内部でこのような、反実仮想機械学習、オフ方策評価・学習が動いています。
結果としてAさんにはクーポン付与の効果が一番高く、Bさんにはポイント付与、Cさんは何もせずとも購入してくれる可能性が高いとなればその方策を設定し、下記のような施策が実施されることとなります。
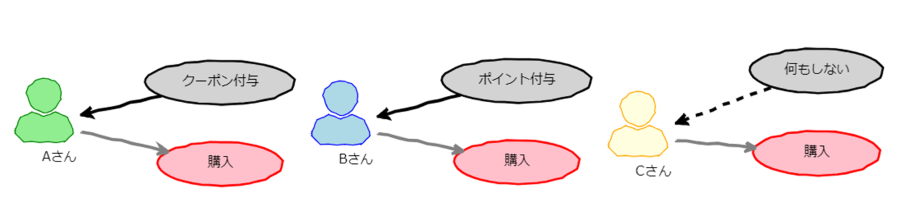
マーケティング施策の例から分かるように、各施策の効果は異なり、また個々の顧客ごとに最適な施策も異なります。十分な量の履歴データがあれば、同様の手法を用いてマーケティング以外でも、例えば従業員満足度向上のために個々に最適な施策を見つけることが可能となります。
まとめ
前回の記事『ビジネスの意思決定に必要な因果推論』では、施策ごとの効果が異なる場合に正しい意思決定を行うためには、各施策の効果を正しく推定する必要があることをお話ししました。
今回は顧客など個々の効果が異なる場合に最適な施策を実施する方法についてお話ししました。引き続き、因果推論をビジネスで活用するために技術動向や手法の調査を進めてまいります。

青木
イノベーション推進部 第一技術室
データサイエンス関連の技術調査に従事




三井情報グループは、三井情報グループと社会が共に持続的に成⻑するために、優先的に取り組む重要課題をマテリアリティとして特定します。本取組は、4つのマテリアリティの中でも特に「情報社会の『その先』をつくる」「ナレッジで豊かな明日(us&earth)をつくる」の実現に資する活動です。
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
本文および図表中では商標マークは明記していない場合があります。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。



