GTC(GPU Technology Conference)とは

NVIDIA GTCは、世界をリードする研究者、開発者、ビジネスリーダーが一堂に会し、AIの最先端技術を活用した取り組みや研究成果を紹介するNVIDIA最大のカンファレンスです。米国カリフォルニア州サンノゼで開催され、AI、グラフィックス、HPCなどの多彩な分野でのセッション講演や、多数のスポンサーおよび関係各社によるブースが並ぶ展示も行われています。
本イベントは、NVIDIA社創業者/CEOのジェンスン フアンによる最先端技術の紹介をする基調講演が有名ですが、期間中はカンファレンスセンターの各部屋で多くのセッション、セミナーが催されています。参加者は聞きたいセッションやセミナーをWebカタログから事前予約し、聴講します。
2025年は3月にNVIDIA GTC 2025が開催されました。25,000名を超える現地参加者があり、昨年と比較しても現地は連日大混雑でした。
三井情報からは4名がGTCへ参加しました。本コラムでは参加エンジニアが現地で体感した最新のトレンド技術と当社の取り組みについてご紹介いたします。
オンプレミスでの生成AI活用
ChatGPTのようなクラウドベースのAI活用が一般的な中、オンプレミスでの生成AI活用も注目を集めています。GTCでも、企業の自社環境で実現可能なAI開発・運用の事例紹介やトレーニングが数多く実施されていました。
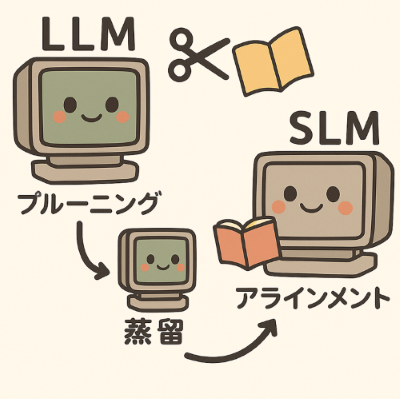
特に注目したのは、SLM(Small Language Model)の開発事例です。SLMはLLMと比較してパラメータ数の小さい(数十億パラメータ以下程度の)軽量なモデルです。限られた計算資源でも動作することから、オンプレミスやエッジ環境に適しています。消費電力が少ない、処理が比較的高速、プライバシー・セキュリティの観点でメリットがあると言われています。GTCのセッションでは、不要な構造を削る「プルーニング」や、大規模なモデルの知識を継承させる「蒸留」、モデルの出力を調整する「アライメント」といった段階的な開発ステップが紹介されていました。これにより、精度を維持しながらも特定業務に適合したより軽いモデルを実現します。
他にも、医療テキストを事例として具体的なコードを交えたLLMのファインチューニングや、モデルの学習パイプラインのリソース管理方法などのトレーニングがあり、オンプレミスでの開発・運用を支える技術知見を得ることが出来ました。
例えば、インフラ構築や製造業など、データを外部に出せない・出したくない現場ではオンプレミスでのLLM活用が求められます。当社でも、オンプレミスLLMの活用によるネットワークインテグレーション業務効率化の研究開発を進めており、今回得られた知見を活用できると考えています。
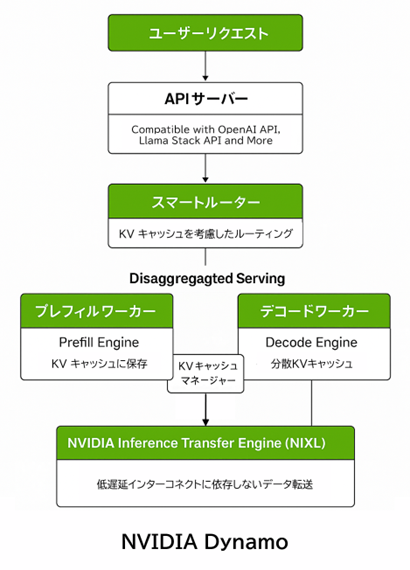
NVIDIA Dynamoで分散推論を高速化
当社が取り組んでいる、AIの有効活用による業務効率化においては、クラウド利用が難しい場合があり、オンプレミスでの生成AIの推論ニーズは今後さらに重要性を増すと予想されます。言語モデルの普及に伴い、推論処理には大量の計算と複雑なメモリ管理が必要となるため、リソースを無駄なく使用し、応答遅延などの使い勝手に関わる課題も考慮する必要があります。
NVIDIAは、GTCでこれらの課題への解決策として「Dynamo」を発表しました。Dynamoは、TensorRT-LLMの技術を土台にしつつ、推論処理を「プレフィル」と「デコード」の2段階に分け、それぞれを個別に最適化することでリソースを効率良く活用し、高速な応答を実現しています。また、KVキャッシュを活用したインテリジェントなルーティングや低遅延なデータ転送機構により、大量の同時リクエスト処理や長文コンテキストへの対応力も高めます。これは、Reasoningモデルの「推論コストとレイテンシー(遅延)」の課題を解決するための分散推論基盤としてとても有効です。
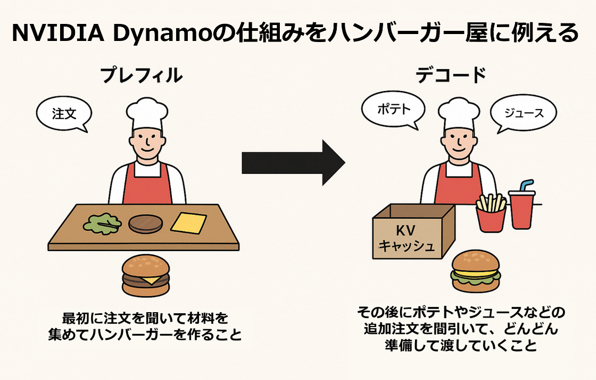
Dynamoの仕組みをハンバーガー屋に例えると、AIが質問に答える過程は、ハンバーガーを作る工程に似ています。プレフィルは、最初に注文を聞いて材料を集めてハンバーガーを作る工程であり、デコードは、ハンバーガーができた後、追加でポテトやドリンクを注文されるように、AIも続く出力(文章生成など)を出す工程を示します。このときの出力は既に使った材料(計算結果)を活かして高速に処理します。
最初(プレフィル)は材料を全部準備するので時間が掛かりますが、後からの注文(デコード)は準備があるためスムーズに進みます。そして、「前に作ったハンバーガーの材料を無駄にしない仕組み」として一度ハンバーガーを作ったあと、残った材料(KVキャッシュ)を箱にしまっておきます。次に同じお客さんがまた追加注文したときに、その箱の材料を使えば、新しく材料を取り出す手間が省け、速く注文を作ることができます。
但し、お客さんの数が増えてくると箱が多くなるため、「どのお客さんにどの箱を渡すか決める」ことが必要になり、これが「KVキャッシュのルーティング」に相当します。お客さんに合った箱を渡し、無駄なくスピーディに注文を作る仕組みです。
このDynamoで得られる性能向上は、高いリアルタイム性と正確性が求められるAI環境において、さらに果的に活用できます。GTCの基調講演内で示されたその効果(応答速度)は、なんと最大30倍です。このような技術を使って、限られた計算リソースを効率良く活用することが、オンプレミスでの成功のカギとなります。
GPUサーバーの水冷化
オンプレミスにて生成AIを利用しようとした場合、GPUサーバーを設置するため、機器から放出される熱が問題になることがあります。
最新のGPUの消費電力は相当なものがあり、具体的にはGPUサーバー1台でこれまでの汎用サーバー数台あるいは10台分以上に相当する消費電力に達します。この膨大な電力から発生する熱を空気で冷やすには限界があります。もう少し正確に書くのであれば金属から空気へ熱を渡す効率の問題で、熱を逃がすためのヒートシンクと呼ばれる部品が巨大化してしまいます。空冷のHGXプラットフォームモデル(例えば NVIDIA DGX™ B300 など)は縦方向の大きさが非常に大きくなり、結果としてサーバーラック一つあたりに搭載できる数が少なくなります。
また、サーバーなどから放出された熱はデータセンターに設置された空調設備によって建屋の外へ放出されますが、これまでとは桁の違う熱量だけに一つの部屋の中で稼働可能なサーバー数がかなり限られる形となることもあります。そのため、大規模なシステムを構築することが物理的な制約から難しくなるケースもあります。

左側は空冷サーバーのイメージ図、高さはほとんどヒートシンクの大きさとなります。 右側は水冷サーバーのイメージ図、筐体内に配管が通り発熱部分に冷却液を届けます、高さはこれまでのサーバーと同様です。
こうした問題を解決するため、最新プラットフォームであるGB200 NVL72等の高集約モデルではDLC(Direct Liquid Cooling)方式の水冷が採用されています。
DLC方式はサーバーやスイッチ筐体内に冷却液の配管が入り込み熱を発するCPUやGPUなどの部品に冷却液を直接届け金属から液体に熱を回収します。この方式では空気より効率的に熱を回収することが可能となり、結果的により多くのマシンを少ない空間に搭載が可能となります。また、サーバールーム内に熱が放出されないためサーバールーム全体での集約度、搭載可能数も向上させることができます。
ただし、このDLC方式ではホースやコネクタ、マニフォールド、CDUなど多くの部品が必要となります。しかしながら、現状、標準化は進んでおらず、業界の中でも数社が競争を行っている状態となっています。また、意外な弱点として水冷機器に障害が発生した場合は接続された機器全ての停止が必要となるケースもあります。冗長構成がどのように構成できるか、緊急時の停止方法とシステム全体でのサービス継続性という観点なども考慮が必要となります。
もちろん水冷についてはデータセンター側での対応状況についても注視が必要です、日本国内ではまだ試験的導入段階であり、全てのデータセンターで気軽に利用が出来るという訳ではありません。
実際の導入にあたっては必要となるシステムの規模感や拡張計画を考慮したうえで水冷が必要なのか、また必要となる場合は水冷機器の詳細な情報についてデータセンター事業者とも密にコミュニケーションを取って導入することが必要となります。
三井情報の取組み「MKI AIシステム リファレンスデザイン」
GTCに参加し、私たちは推論モデルの登場により高度・複雑化する推論処理をより高速で提供できるシステムの必要性と実運用上求められるセキュリティや継続的なモデル・データ改善の必要性を肌で実感しました。
オンプレミスAI環境の構築は、いまやサーバー・ネットワークといったインフラだけでなく、モデル学習からリアルタイム推論まで一気通貫で最適化された“AIシステム”として設計することが成功の鍵となっています。
当社は以下の取組みを通じ、GPUサーバーだけにとどまらず、モデルや学習・推論プラットフォームを含めた“AIシステム”として、国内のお客様にフィットするセキュリティを確保した形での設計を進めています。
●ソフトウェア/プラットフォーム/ハードウェア各領域のスペシャリストが横断的に協働し、技術力を結集
●各パートナー企業との最新技術情報の共有および最新製品の検証
●国外を含めたイベント参加等を通じた最新動向調査
さらに、複数団体での共同利用を見据えた当社オリジナルのリファレンスデザインを継続して研究・改善して参ります。
今後も三井情報では、最新技術の動向を積極的に取り入れ、お客様の課題解決に貢献してまいります。AIシステムや当社の取組みにご興味をお持ちいただけましたら、どうぞお気軽にご連絡いただけますと幸いです。

山田 (写真左上)
イノベーション推進部 第一技術室
AIに関連した技術調査、研究開発を推進。
武井 (写真右上)
イノベーション推進部 第二技術室
ITインフラ領域において、これまでコンテナ技術や仮想化、ネットワーク技術の分野で経験を積み、現在はイノベーション推進部に所属し、研究開発を通じた新たな価値創造を推進中。
菊島 (写真下)
イノベーション推進部 第二技術室
サーバー・ストレージに関する次世代技術研究および研究派生の新規プロダクト開発に従事。




三井情報グループは、三井情報グループと社会が共に持続的に成⻑するために、優先的に取り組む重要課題をマテリアリティとして特定します。本取組は、4つのマテリアリティの中でも特に「情報社会の『その先』をつくる」「ナレッジで豊かな明日(us&earth)をつくる」の実現に資する活動です。
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
本文および図表中では商標マークは明記していない場合があります。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。



