はじめに
生成AIや自動運転、ロボットのニュースのなかで、「世界モデル(World Model)」という言葉を目にされた方も少なくないと思います。世界モデルはAIエージェント関連の技術として特に注目されています。一方で、予測・シミュレーション基盤として動画生成や意思決定支援など幅広い領域とも深くかかわりつつあります。
とはいえ、
- 世界モデルとは何か
- ビジネスにとって何が嬉しいのか
といった点は、分かりにくいと感じる方も多いのではないでしょうか。本コラムでは数式には踏み込まず、世界モデルをご紹介します。
世界モデルとは何か?
世界モデルの発想
人はいつも「頭の中で世界をシミュレーション」している
例えば、野球においてバッターがボールを打つときを考えてみましょう。ピッチャーがボールを投げてからバットを振っているのでは間に合わないと考えられています。ではなぜ、打てるかというと、
- 投手の動きなどから「ボールはこのあとこう動くだろう」と予測する。
- その予測に基づいて、体を先回りして動かす。
このように私たちは、外の世界を頭の中で簡略化して再現し、未来をシミュレーションしてから行動しています。心理学ではこうしたものを「内部モデル」あるいは「メンタルモデル」と呼んでいます。
世界モデルとは、これとよく似た仕組みをコンピュータの中に作ろうという発想です。
世界モデルの定義
初期の代表的な世界モデルの一つであるHaらの2018年の論文"World models"(*1) にこの野球の例は出てきます。また、その論文の中では、
Our world model can be trained quickly in an unsupervised manner to learn a compressed spatial and temporal representation of the environment.
訳)我々の世界モデルは、教師なし学習で素早く学習でき、環境の空間的・時間的な表現を圧縮した表現を獲得できる。
つまり、「環境の生成モデルであり、観測から圧縮された時空間表現を学ぶ」と世界モデルを説明しています。
また、世界モデルの研究を網羅的に調査したDingらの2025年のサーベイ"Understanding world or predicting future? a comprehensive survey of world models"(*2) では、
Generally, world models are regarded as tools for either understanding the present state of the world or predicting its future dynamics.
(中略)
two primary functions: (1) constructing internal representations to understand the mechanisms of the world, and (2) predicting future states to simulate and guide decision-making.
訳)
一般に世界モデルは、現在の世界状態を理解するため、または未来のダイナミクスを予測するための道具とみなされる。
(中略)
(世界モデルには)2つの主要機能がある:(1) 世界のメカニズムを理解するための内部表現の構築、(2) 意思決定をシミュレートし導くための未来状態の予測。
研究途上ですのでしっかりとした定義があるわけではありませんが、つまり「世界モデル」とは(AIが)環境(これを「世界」と呼んでいる)を理解し、環境の未来の状態を予測して、意思決定(行動を含む)の判断材料とする働きをするものと言えます。
(*1) HA, David; SCHMIDHUBER, Jürgen. World models. arXiv preprint arXiv:1803.10122, 2018. Available at: https://arxiv.org/abs/1803.10122 (Accessed: 2026-03-03).
(*2) DING, Jingtao, et al. Understanding world or predicting future? a comprehensive survey of world models. ACM Computing Surveys, 2025, 58.3: 1-38. Available at: https://dl.acm.org/doi/10.1145/3746449 (Accessed: 2026-03-03).
世界モデルの2つの役割(理解/予測)
以上から、世界モデルの役割を大きく次の2つに整理できます。
- 世界を理解する(内部表現)
- カメラ画像、センサー値、テキストなど大量の観測データから、「今なにが起きているか」を少数の変数に圧縮して表現する。
- たとえば「この物体は人」「こちらは車」「向こうから近づいている」といった、状態の「要約」を自動で作るイメージ。
- 未来を予測する(シミュレーション)
- 「今の状態」と「もしこう行動したら」を入力すると、「数秒後にはこうなっているはず」という未来の状態を予測する。
- これを高速に何度も回すことで、実世界で試す前に頭の中で「もしも」を検証できる。
この2つが組み合わさることで、AIは「状況を理解し、先を見通してから行動する」ことが可能になります。
従来のAIと何が違うのか(AIエージェントで効く理由)
従来のAIの単発の入出力(分類・生成・対話)に比べ、AIエージェントは観測→計画→実行→更新のループが本体となります。
例えばChat型のAIは、ユーザのプロンプトによる指示に対し何らかの結果を返答します。ところがより複雑な指示、時々刻々と環境が変化するような状況で長時間かけて複雑なタスクを実行し目的を達成しなければならない、となった場合には、
- 環境がどうなっているかの環境理解
- 環境の状態がどう変化するかの未来予測
を自律的にAIが判断し、それを元に行動計画を立てて実施する必要があります。ユーザの指示に対し自律的に判断と行動が出来る、いわゆる「AIエージェント」が必要となります。
つまり、AIエージェントの内部で世界モデルが働き、
- ユーザの指示に対し、
- AIエージェントが環境から観測データを得て、
- それを世界モデルが環境を理解し、未来の環境の状態を予測する。
- その結果を元にAIエージェントが行動計画を立てて環境に対して何らかの行動を行う。
- これを繰返すことでユーザの指示を達成し、
- 結果をユーザに返す。
このような仕組みの中で世界モデルが役立ちます。
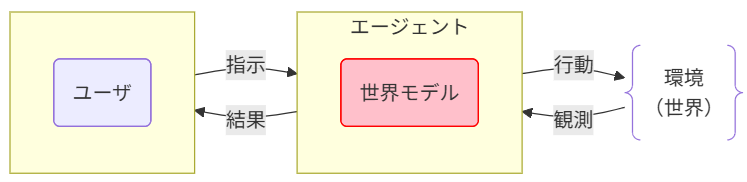
どう動く?(Dreamerの例:「AIが夢を見る!?」)
世界モデルには複数の実装があります。ここでは代表例としてDreamer系と呼ばれる手法の内部構造の概要をご紹介します。
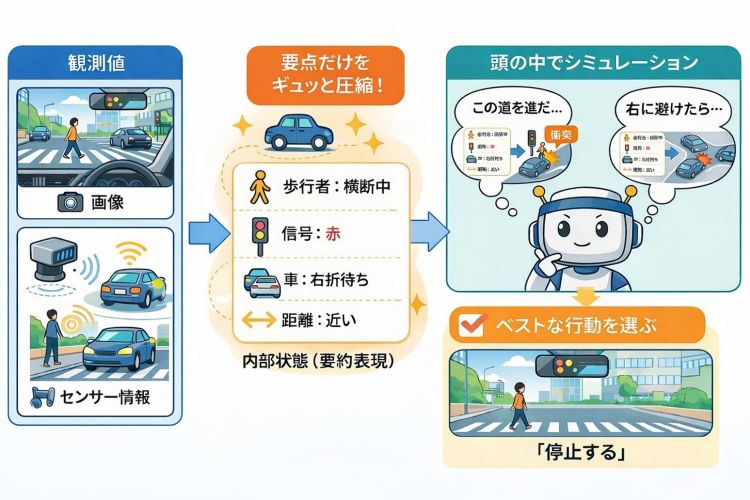
- カメラやマイク、センサーなどで外界の環境を「観測」したデータを観測値として得る。
- その観測値をAIエージェントが判断に使えるよう、要点だけを残した「内部状態(要約表現)」に圧縮する。
- その内部状態の中で「もしこう動いたら?」を試しながら次にどうなるかを予測する(シミュレーションする)。
- 環境理解と未来予測の情報をAIエージェント側に渡し、AIエージェントが行動計画を立て実行する。
これを繰返します。
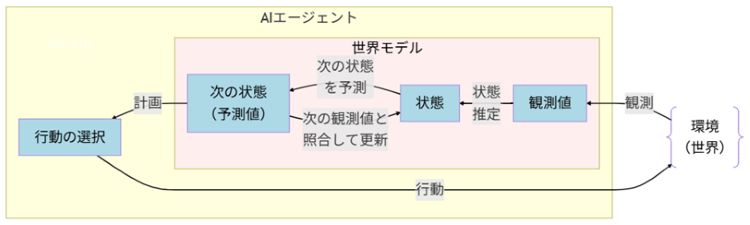
この手法では、環境の観測値(画像やセンサー値)をそのまま扱うのではなく、意思決定に必要な要点だけを残した「内部状態(要約表現)」にまとめます。そして、その内部状態の中で「もしこの行動をしたら次はどうなるか」を何度も試し、良さそうな行動を選びます。現実で試す前に、頭の中で未来をリハーサルするイメージです。
もちろん「AIが夢を見る」ことはありませんが、Dreamerと名付けられた研究の論文では、この頭の中で試すことを”latent imagination(潜在空間での想像)”と呼んでおり、「AIが夢を見る」という比喩はここから連想できます。
ビジネスにとって何が嬉しいのか
世界モデルの活躍の場は?
世界モデルは、状況の把握と未来予測を「シミュレーションとして回せる」点が強みです。これにより、試行錯誤コストの削減、安全性の向上、意思決定の質の向上が期待できます。
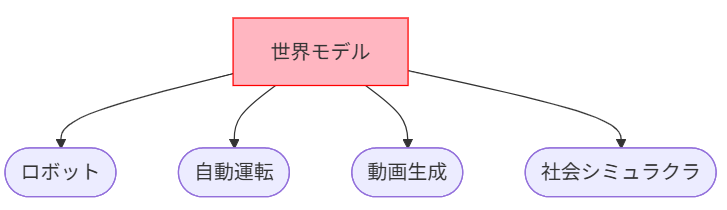
- ロボット
- 工場内のアームロボットや倉庫ロボットが、周囲の配置や人の動きを内部モデルとして学習し、「物を落とさずに素早く運ぶには」「人にぶつからない経路は」といった行動をシミュレーションできます。
- 世界モデルを使うことで、現実での試行を減らしつつ、新しい作業手順を学習できる可能性が示されています。
- 自動運転
- カメラやLiDAR(レーザー光による測定技術)の情報から「他車・歩行者・信号などの配置」と「数秒先の動き」をまとめて予測する研究が進んでいます。
- 雨天・渋滞・事故など多様なシナリオを、現実の道路ではなくシミュレーション上で大量に経験させることで、安全性と検証の低コスト化の両立を目指しています。
- 動画生成
- テキストから高品質な動画を生成するモデル(例:OpenAIのSoraなど)は、「物体がどう動くか」「影や水しぶきがどう変化するか」といった物体の動きや相互作用など、物理的ダイナミクスをある程度捉えている可能性が指摘され、世界モデル的に捉える議論もあります。
- 社会シミュラクラ(Social Simulacra)
- 従来の「社会シミュレーション」よりも個々人をより具体的に描くことを目指す研究分野です。
- LLM(大規模言語モデル)をベースにした「会話するAIエージェント」が、仮想の町の住人として生活し、互いに影響し合う「社会シミュレーション」の研究も進んでいます。
- ここでは「人間同士のやりとり」が世界モデルの対象となり、たとえばマーケティング施策の影響を仮想社会で試す、といった使い方などが研究されています。
世界モデルの「今の限界」
世界モデルは魅力的な技術ですが、現状では次のような課題も明らかになっています。
- 長期予測の難しさ
- 数ステップ先までは高精度に予測できても、数分先となると誤差が蓄積し、シミュレーション結果が現実から大きく外れてしまうことがあります。
- 未知の状況への一般化
- 訓練データに含まれていない「レアケース」や「環境の変化」に弱く、実社会への適用では汎化能力が大きなボトルネックになっています。
- 計算コストとインフラ
- 高精細な映像や3D情報を扱うマルチモーダル世界モデルは、学習・推論ともにGPUリソースを大量に必要とします。
- 現状ではクラウド前提の実験も多く、リアルタイム処理やエッジ実装には工夫が必要です。
- 安全性・説明可能性
- 「なぜその予測をしたか」「どのシミュレーション結果をもとに判断したか」がブラックボックスになりがちです。
- 自動運転や医療など、安全性が重要な領域では、説明可能性と検証方法が重要な論点です。
ビジネス視点で押さえておきたいポイント
世界モデルは「今すぐ導入する技術」というより、中長期的にAIエージェントの競争力を左右する基盤技術として捉えるのが現実的です。
ビジネスの立場からは、次のような観点が重要になります。
- 「より賢い予測・シミュレーション基盤」として捉える
- 世界モデルは魔法のようなAIではなく、「多様なセンサー情報をまとめ、未来をシミュレーションするエンジン」と考えるとイメージしやすくなります。
- 既存のビジネス状況に、「もしこの施策を打ったらどうなるか?」というシミュレーションが低コストで行えるという考え方を持ち込むことが一つの方向性です。
- Physical AIとの親和性が高い
- ロボットや自動車などの物理的な身体を持ち、センサーを通じて現実世界(物理空間)を理解し、自律的に行動するAI技術であるPhysical AIが重要となってきておりますが、そのためには世界モデルの活躍の場が広がると思われます。
- LLM・因果推論との組み合わせが鍵
- 世界モデル単体では「映像的な予測」は得意でも、「なぜこうなったか」という因果の理解はまだ十分ではありません。
- より精度よく「環境を理解」するために、LLMの知識や因果推論との統合が、今後の重要な研究テーマとして挙げられています。
- 評価指標とガバナンスの設計が不可欠
- 「どの範囲なら世界モデルの予測を信頼するのか」「どこからはルールベースや人間が最終判断するのか」といったガバナンス設計をあらかじめ決めておくことが、安全な活用には欠かせません。
おわりに
世界モデルは、AIエージェントが「世界を頭の中で再現し、未来を思い描いてから行動する」ための技術です。ロボットや自動運転だけでなく、動画生成、社会シミュラクラなど、幅広い領域で基盤技術となっていくことが期待されています。
一方で、長期予測の信頼性やレアケースへの対応、安全性・コストといった課題もまだ多い状況です。
当社のPurpose「ナレッジでつなぐ、未来をつくる」に則り、単にAIの実装だけではなく、AIでどう未来をつくるか、の1つの手段として世界モデルを調査し、ご紹介しました。
本コラムが、皆さまのビジネスにおける「世界モデルとの付き合い方」を考えるきっかけになれば幸いです。

青木
イノベーション推進部 第一技術室
データサイエンス関連の技術調査を担当




三井情報グループは、三井情報グループと社会が共に持続的に成⻑するために、優先的に取り組む重要課題をマテリアリティとして特定します。本取組は、4つのマテリアリティの中でも特に「情報社会の『その先』をつくる」「ナレッジで豊かな明日(us&earth)をつくる」の実現に資する活動です。
コラム本文内に記載されている社名・商品名は、各社の商標または登録商標です。
本文および図表中では商標マークは明記していない場合があります。
当社の公式な発表・見解の発信は、当社ウェブサイト、プレスリリースなどで行っており、当社又は当社社員が本コラムで発信する情報は必ずしも当社の公式発表及び見解を表すものではありません。
また、本コラムのすべての内容は作成日時点でのものであり、予告なく変更される場合があります。




